在寫 concurrency 程式時,通常會用 lock、synchronized 等機制保護存取共享資源的程式片段,確保一次只有一個 thread 可以使用這些共享資源。
但若是共享資源不是一個程式片段而僅僅只是一個變數,使用 lock、synchronized 等機制就會顯得太笨重,甚至拖慢效能。
以下面的 Golang 程式來說:
func BenchmarkLocke(b *testing.B) {
for n := 0; n < b.N; n++ {
a := 0
var l sync.Mutex
for i := 0; i < 10000; i++ {
l.Lock()
a++
l.Unlock()
}
}
}profiling 這段程式以後會發現 CPU 時間幾乎都花在 Lock 上面,下為 profiling 結果:
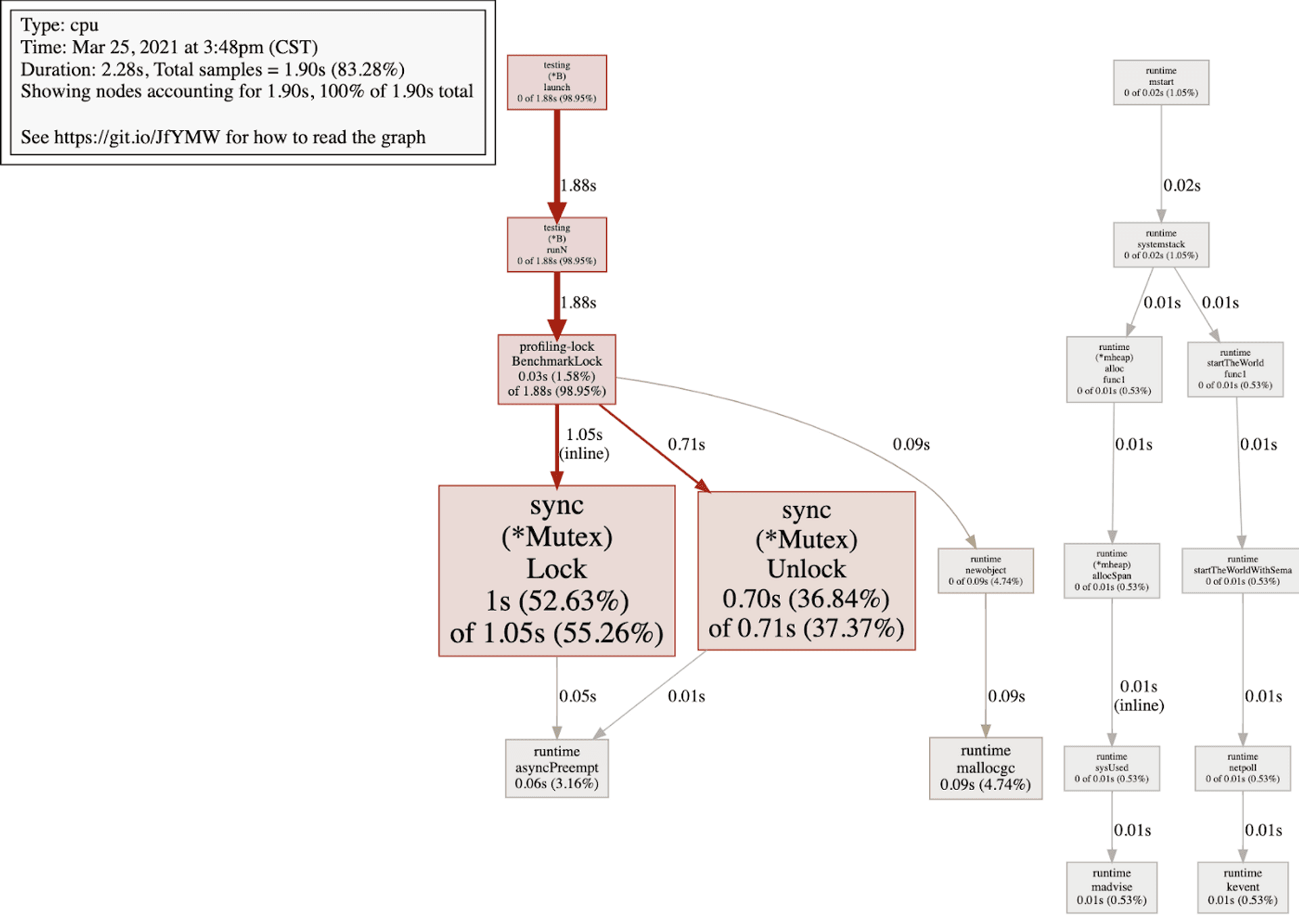
為了提升效能,保護單一變數在多個 thread 共用會用 lock-free 等手法。 而在撰寫 concurrency code 處理共享變數問題時,有三件事要注意:原子性 (atomicity)、可見性 (visibility) 以及有序性 (ordering)。
本文就這三個議題,分別探討 Java 和 Golang 提供那些機制來處理,在此之前,我們先介紹一下這三個議題:
# 原子性
共用變數的操作需確保不會被中斷。一行程式碼可能由多個 cpu 指令組成,例如說 i++,就是由從變數取值,值加一,賦值回變數三個 cpu 指令。若是兩個 thread 同時執行 i++ 時,cpu 指令執行順序可能是這樣交錯執行:
thread1 讀值 100
thread2 讀值 100
thread1 加一 101
thread2 加一 101
thread1 賦值 101
thread2 賦值 101
因此會得到一個錯誤的結果,i=101。
一個簡單的 java 範例如下
public class Atomic {
public static void main(String []args) throws InterruptedException {
int times = 100000;
ExecutorService executorService = Executors.newFixedThreadPool(1000);
Counter counter = new Counter();
for (int i=0;i<times;i++) {
executorService.execute(new Thread(() -> {
counter.i++;
}));
}
Thread.sleep(20000);
executorService.shutdown();
System.out.println(counter.i);
}
static class Counter {
int i;
}
}第 16 行預期應該顯示 100000,但實際執行往往少於 100000。這就是因為共享變數的存取沒有保持一致性導致的。
# 可見性
在多核環境,每個 CPU 都會有專屬自己的 cache,原本的用意是用來減少直接跟 memory 溝通的次數以提升效能。下圖即為一個簡單的 cpu架構示意圖。

這此架構下,同一個變數可能存在多個 cpu 快取中,若是 cpu1 更新了變數而 cpu2 毫無所知的話,cpu2 上的 thread 就會一直使用舊的值。
下面是一段 java 範例:
public static void main(String []args) throws InterruptedException {
Flag flag = new Flag();
Thread t1 = new Thread(()->{
while(flag.bool) {
// do nothing
}
});
t1.start();
Thread t2 = new Thread(()->{
flag.bool = false;
});
t2.start();
t1.join();
System.out.println("Unreachable");
}
static class Flag {
boolean bool = true;
}即使 thread 2 已經將 flag 更新為 false,但 thread 1 仍有一定機率會一直卡在 for loop 無法逃脫,因為 thread 1 沒看到 thread 2 對 flag 的更新。
# 有序性
編譯器在把程式碼轉成 cpu 指令的時候有時會因為效能因素重排指令,這會導致實際 cpu 執行指令的順序和你想像的不太一樣。例如下面三行 code:
a = 1
b = 2
c = a + b第三行相依前兩行 code,因此 compile 只會保證前兩行在第三行前執行,亦即m是實際上執行順序可能會是
b = 2
a = 1
c = a + b這在 signle thread 是沒問題的,但在 multi thread 情況下亂序可能會造成你無法理解的 bug。以下是一個簡單的 Java code 範例:
private static int a=0,b=0;
public static void main(String[] args) throws Exception {
int i=0;
for (; ;) {
i++;
Thread t1 = new Thread(()->{
a=2;
b=1;
});
t1.start();
if (b==1 && a==0) {
String err = String.format("%th round, Non thread safe!", i);
System.err.println(err);
break;
}
t1.join();
}
}是很有可能進入進入 12~16 行的 if condition 的,因為對 thread t1 而言 a=2 和 b=1 兩件事沒有 happen-before 關係,所以不會保證順序。
上面提到的三個 concurrency 問題,其中可見性 (visibility) 和有序性(ordering) 通常一起通稱為 happen-before 原則。
在實作 singleton 模式時常使用 “Double-checked locking” 來優化效能,此時若沒有意識到 happen-before 便會遇到問題:即使 singleton 物件非為 null 也不保證該物件處於初始化完成的狀態,因此有可能會讓系統異常,可參考 wiki 對此異常的描述文章。
接下來看看 Java 和 Golang 怎麼處理這些問題。
# Java
# Java 如何處理原子性?
Java 在 java.util.concurrent.atomic 裡面提供了原子性操作相關的 tool kit,用來保證變數的操作。例如可以用 AtomicInteger 來處理對共享變數的操作,如此即可保證原子性不被破壞,得到正確的結果,修改過如下
public static void main(String []args) throws InterruptedException {
int times = 100000;
ExecutorService executorService = Executors.newFixedThreadPool(1000);
Counter counter = new Counter();
for (int i=0;i<times;i++) {
executorService.execute(new Thread(() -> {
counter.i.incrementAndGet();
}));
}
Thread.sleep(20000);
executorService.shutdown();
System.out.println(counter.i.get());
}
static class Counter {
AtomicInteger i = new AtomicInteger(0);
}# Java 如何實作 happen-before?
Java 提供了 volatile 關鍵字用來處理 happen before,一但變數在宣告時加上 volatile,對該變數的存取即保證可見性和有序性(注意,原子性不在保證內)。以下便是將開頭講的兩個可見性和有序性的例子,使用 volatile 關鍵字宣告共有變數,便可以保證 happen-before。
以開頭第二個可見性的例子來說:
public static void main(String []args) throws InterruptedException {
Flag flag = new Flag();
Thread t1 = new Thread(()->{
while(flag.bool) {
// do nothing
}
});
t1.start();
Thread t2 = new Thread(()->{
flag.bool = false;
System.out.println(flag.bool);
});
t2.start();
System.out.println(flag.bool);
t1.join();
System.out.println("Unreachable");
}
static class Flag {
volatile boolean bool = true;
}當 flag 使參數使用 volatile 修飾後,thread t1 會馬上感知到 thread t2 在第 12 行對 flag 的異動,到 main memory 讀取最新的值,然後逃離迴圈。
而以有序性的例子來看 volatile:
private volatile int a=0,b=0;
public static void main(String[] args) throws Exception {
int i=0;
for (; ;) {
i++;
Thread t1 = new Thread(()->{
a=2;
b=1;
});
t1.start();
if (b==1 && a==0) {
String err = String.format("%th round, Non thread safe!", i);
System.err.println(err);
break;
}
t1.join();
}
}加入 a, b 兩個變數加入 volatile 修飾後,即可確保 a 之前的 code 一定會在 a 之前執行,b 之前的 code 一定會在 b 之前執行,因此 thread t1 的 CPU 指令會保證執行順序一定是 a=2, b=1。而對 main thread 而言,就永遠不會看到 b=1, a=0 這種亂序行為了。
# Golang
# Golang 如何處理原子性?
Golang 也有提供自己的 atomic tool kit,還記得最開頭使用 Lock 的 Golang 範例嗎? 可以改成用 atomic 來處理如下:
func BenchmarkFib10(b *testing.B) {
for n := 0; n < b.N; n++ {
a := int64(0)
for i := 0; i < 10000; i++ {
atomic.AddInt64(&a, 1)
}
}
}可以用 atomic 替換掉 Lock,同時達到原子性效果。
附上兩種寫法的 benchmark:
BenchmarkLock-8 9266 134075 ns/op 8 B/op 1 allocs/op
BenchmarkAtomic-8 19225 62309 ns/op 8 B/op 1 allocs/op相較之下可以看到 Lock 的確很吃效能。下圖附上對 atomic 範例的 profiling
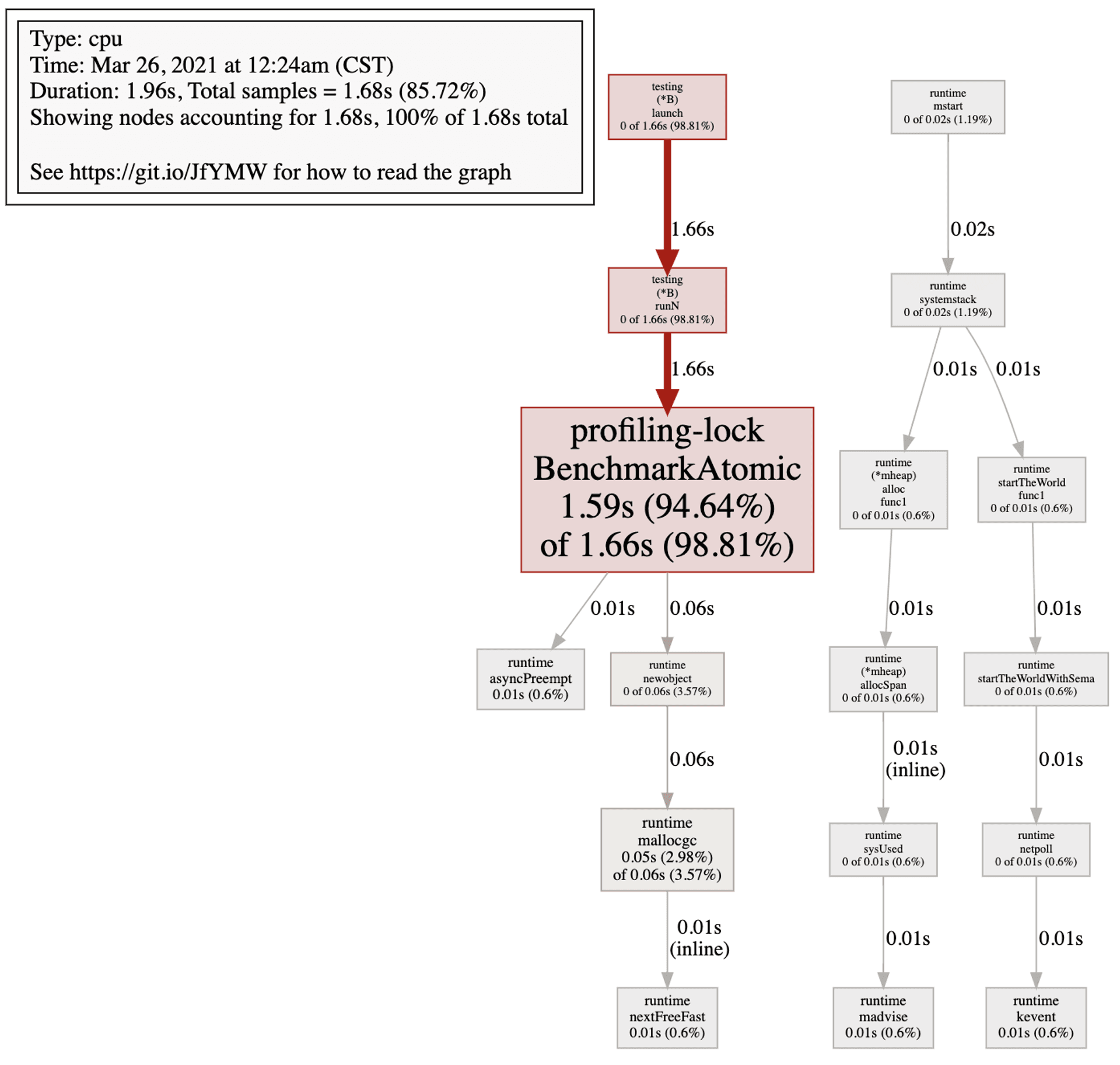
可以看到 cpu 並沒有花太多時間在處理同步上。
# Golang 如何實作 happen-before?
根據 Golang 官方 blog 說明了下面幾種情況 Golang 保證 happen before:
- Initialization
- Goroutine creation
- Goroutine destruction
- Channel communication
- Locks
- Once
但美中不足的是 Golang 並沒有像 Java 的 volatile 可以保證某個變數的 happen before。
已可見性來說,下面這段 code:
func main() {
flag := true
go func() {
for flag {
continue
}
fmt.Printf("Never end\n")
}()
flag = false
for {
continue
}
}第 5~10 行的 goroutine 會卡在無窮迴圈。
再說有序性,官網 blog 即有提到下面這段 code 不是安全的 concurrncy code:
var a, b int
func f() {
a = 1
b = 2
}
func g() {
print(b)
print(a)
}
func main() {
go f()
g()
}這段 code 是有可能先 print 2 再 print 0,因此跨 goroutine 的共有變數使用時,若遇到類似上述的 code,務必要用 lock 等有保證 happen before 的機制保護。
為了確保有序性和可見性,若真需要共享變數還是必須在變數前後用笨重的 Lock 保護。但高效的 Golang 怎麼會用這麼低效的解法?
在這篇官網的 blog 中我們或許可以找到更適合 Golang 的解法。文章中提到
Do not communicate by sharing memory; instead, share memory by communicating.
這也是 Golang 設計 concurrency model 的初衷,使用 CSP model。因此我認為用 channel 來處理可見性和有序性的問題或許是比較 Golang 的做法(如果你還有印象的話,Golang 在 channel 的溝通是有保證 happen-before 的)。
如可見性範例可以用 chan 在不同的 goroutine 間傳遞 flag 的值:
func main() {
done := make(chan bool)
go func(done <-chan bool) {
flag := true
for flag {
select {
case flag = <-done:
break
}
}
fmt.Printf("End of goroutine\n")
}(done)
done <- false
close(done)
for {
continue
}
}而有序性範例也可以用 chan 來傳遞 a, b 的值,因此寫起來可能會像下面這段 code
var a, b int
func f(done <-chan interface{}) (<-chan int, <-chan int) {
chana := make(chan int)
chanb := make(chan int)
go func() {
defer close(chana)
defer close(chanb)
chana <- 1
chanb <- 2
for {
select {
case <-done:
return
}
}
}()
return chana, chanb
}
func g() {
print(b)
print(a)
}
func main() {
done := make(chan interface{})
defer close(done)
chana, chanb := f(done)
a = <-chana
b = <-chanb
g()
}# 結論
撰寫 concurrency 的程式最困難的地方是,很多 bug 都是不確定的,無法複製的,這加大了 debug 的難度。
深入瞭解 concurrency 的議題,以及你寫的每一行 code 背後是如何運行的,可以很大程度的幫助我們避免做錯事。同時,了解這些可以讓我們更體會語言的設計理念,也能幫助我們更好的撰寫符合該語言特性的安全高效 concurrency 程式。
Tag
Recommendation
Discussion(login required)