
如果你用的資料庫是屬於 Relational Database ,在這個年代用SQL進行資料庫的存取已經變成一件理所當然的事了。MySQL 、PostgreSQL 、MsSQL…不論是開源抑或是由大廠主導的 SQL 專案都擁有各自的擁護者 。
其實如果單純以使用與操作的角度去這些不同的資料庫的官網和 document 看過一圈,可能不太容易看出有什麼關鍵性的差異。然而儘管這些資料庫在表面上看起來都提供了類似 Function ,但是對於同樣的一個邏輯, 不同家的資料庫之間的底層的物理實作卻有不少大相徑庭的地方。
這篇文章想要以 MySQL (在本文中所參考的儲存引擎為 innodb ) 和PostgreSQL 為例,來討論一些 Relational Database 在底層操作資料時的一些基本原理。 更確切地說,從DB系統管理Index的方式來切入。
# Indexes : 決定資料存取速度的關鍵
首先來談談 MySQL 和 PostgreSQL 在資料儲存上最關鍵的差異 : Indexes 。
網路上的教學都會說, 對於 table 中經常需要用來當作查詢依據的 column ,把它設成 index 速度就會提升。這背後的原因是因為對於資料庫背後儲存資料的 Data structure 來說 ,被選為 Index 的 Column 就會成為資料結構中的排序依據。
“假設”某個資料庫背後是用 Binary Tree(實際上通常是 B-Tree 的各種延伸版本)來當作核心資料結構的話,一筆資料的 row 就是一個 node。 那例如說在下圖的資料結構,一筆資料會有Name、Height、id 三個欄位,那當我們把欄位 “ id” 設為 index的話 ,這棵樹(也就是資料庫存放資料的結構)就會照著 id 的值來排序。
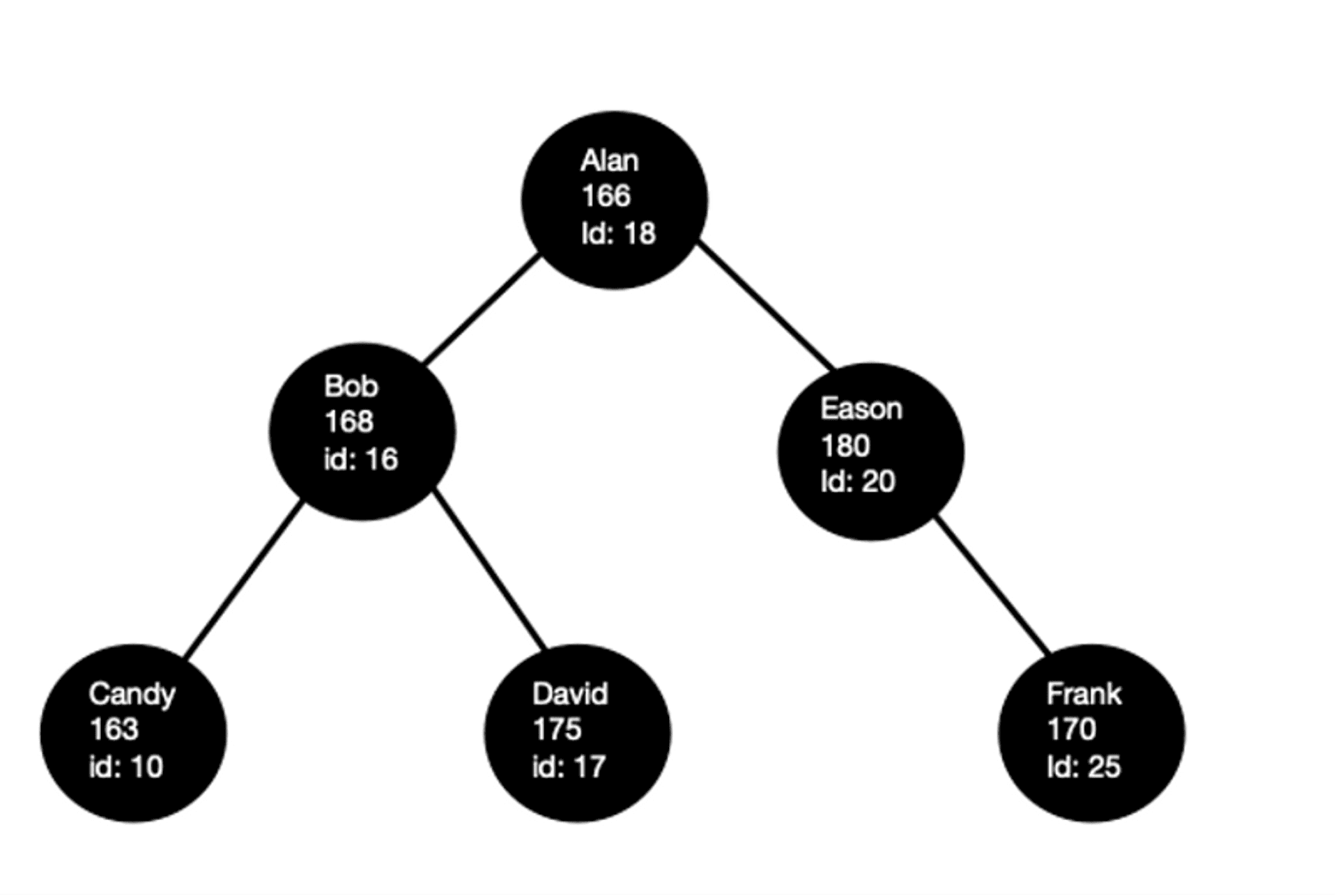
看到這裡有自己設計過 DB Schema 的朋友們可能就會好奇,
“咦但是有時候我同一張 table 裡面會有好幾個 column 會設成 index 耶
那這樣資料庫要以哪個為基準排序啊?”
在討論這個問題前我們必須先瞭解兩個概念:clustered index 和 non-clustered index。
# Clustered Index 與 Non-Clustered Index
如果要用一句話概括說明這兩者的差異,可以說 Clustered Index 是“完整資料(包含所有 column)在 Storage 中實際上的排序依據 ” 而 Non-clustered Index則是 “跟完整資料分開來放的欄位子集合的排序依據”。
說得白話一點就是完整的資料在 storage 裡面用 clustered-index 當作排序依據, clustered-index 相近的資料在 storage 中也會在比較接近的位置。 且因爲他是實際上 storage 在 partition 資料時的依據,所以只能有一個 clustered index。
而資料庫會另外複製幾份被使用者選為 non-clustered index 的 column 資料, 在其他 storage 的空間創造只包含這些 non-clustered index 的資料結構。每多一個 index 就多創造一份。而這些 non-clustered index 跟實際上 storage中的資料的物理位置沒有直接的關連。
以上面的例子為例, id(預設是 Primary Key)就是 clustered index ,而如果使用者在 name 和 height 上都 create index 的話(預設狀況 create 新的 index 就是 non-clustered index),資料庫會創造出額外的兩份複製的子集合資料結構。
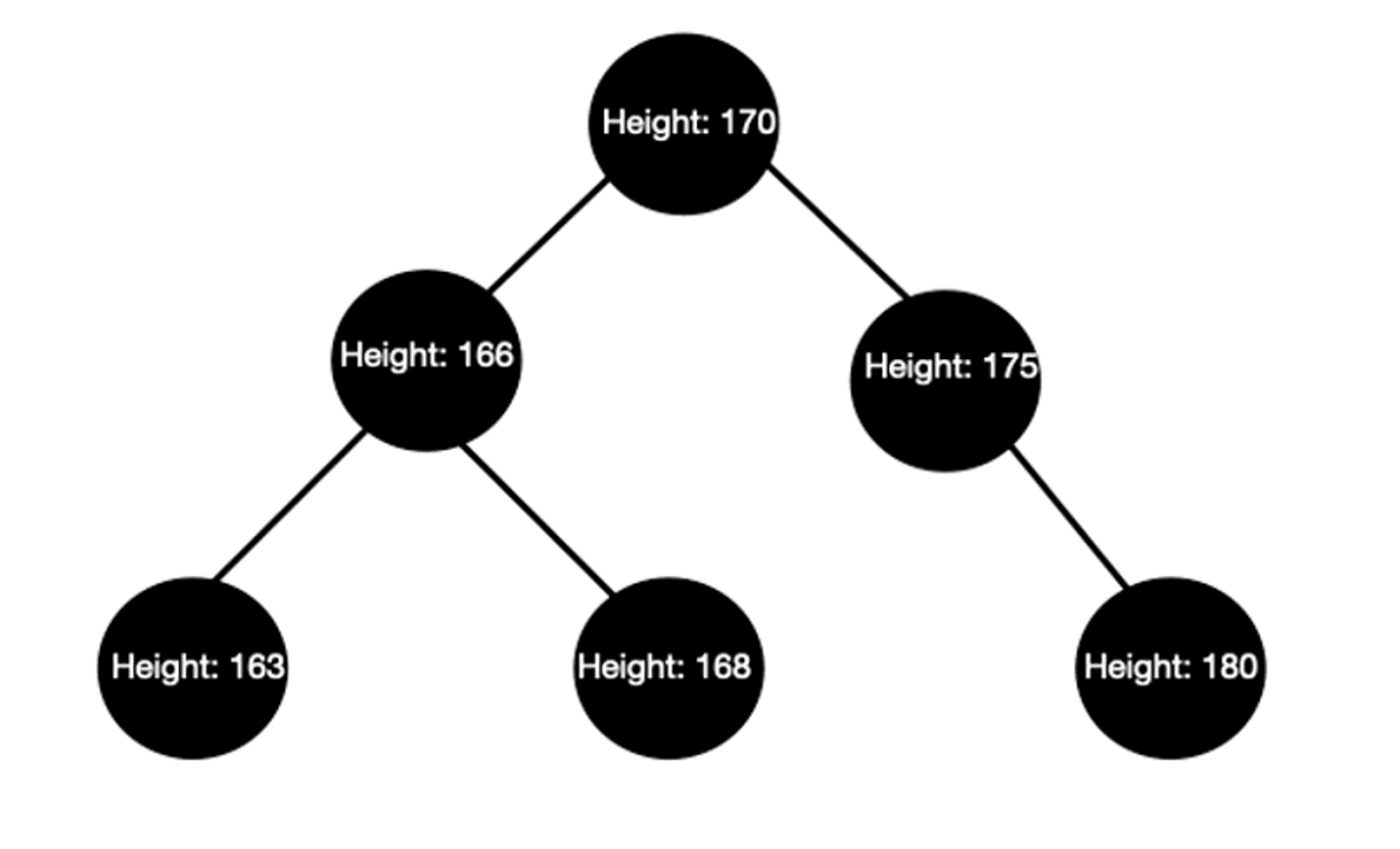
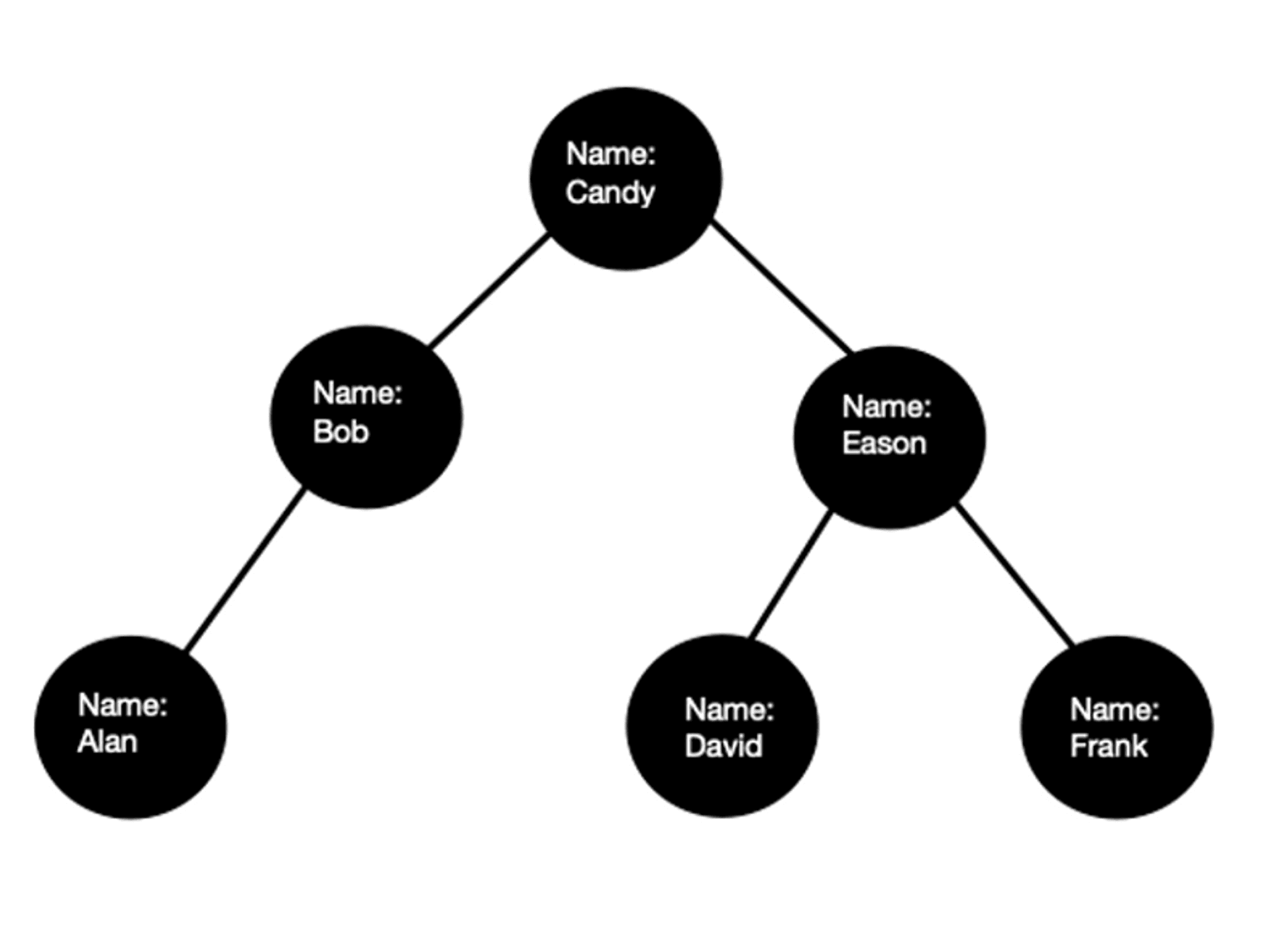
這兩個新的 tree 分別各自以不同的 non-clustered index 進行排序.。當使用者要查詢資料時, 資料庫就會從判斷指令中的條件使用的欄位是否是有被設為index 的欄位,有的話就會從對應的 tree 裡面尋找。
例如下 SELECT * WHERE Height > 165 ,資料庫不會從圖一中原本包含完整資料的結構中尋找, 而是會從複製出來的圖二的結構中尋找對應的 node。
然而眼尖的朋友可能發現, 如果是**SELECT ***的話,就算在圖二的 tree 中找到了需要的 nodes,裡面也沒有包含其他欄位的資料讓我回傳啊!
一個可能的解法是在 create index 時下INCLUDE clause ,可以讓資料庫在創建新的 non-clustered index tree 時把被 include 的欄位資料一起放進去。 但是如果 table 中的欄位很多,那這樣每次要 create 新的 index 時創造出來的新的tree 就會無敵大,對 storage 是一個大負荷。
所以實際上除了用 clustered index 排序的原本資料外,這些額外的 index tree的節點都還包括了一個 field,放的正是 clustered index。 例如圖二以 height 當non-clustered index 的 tree 中實際上會有額外對應的 clustered index (此例中也就是 id )
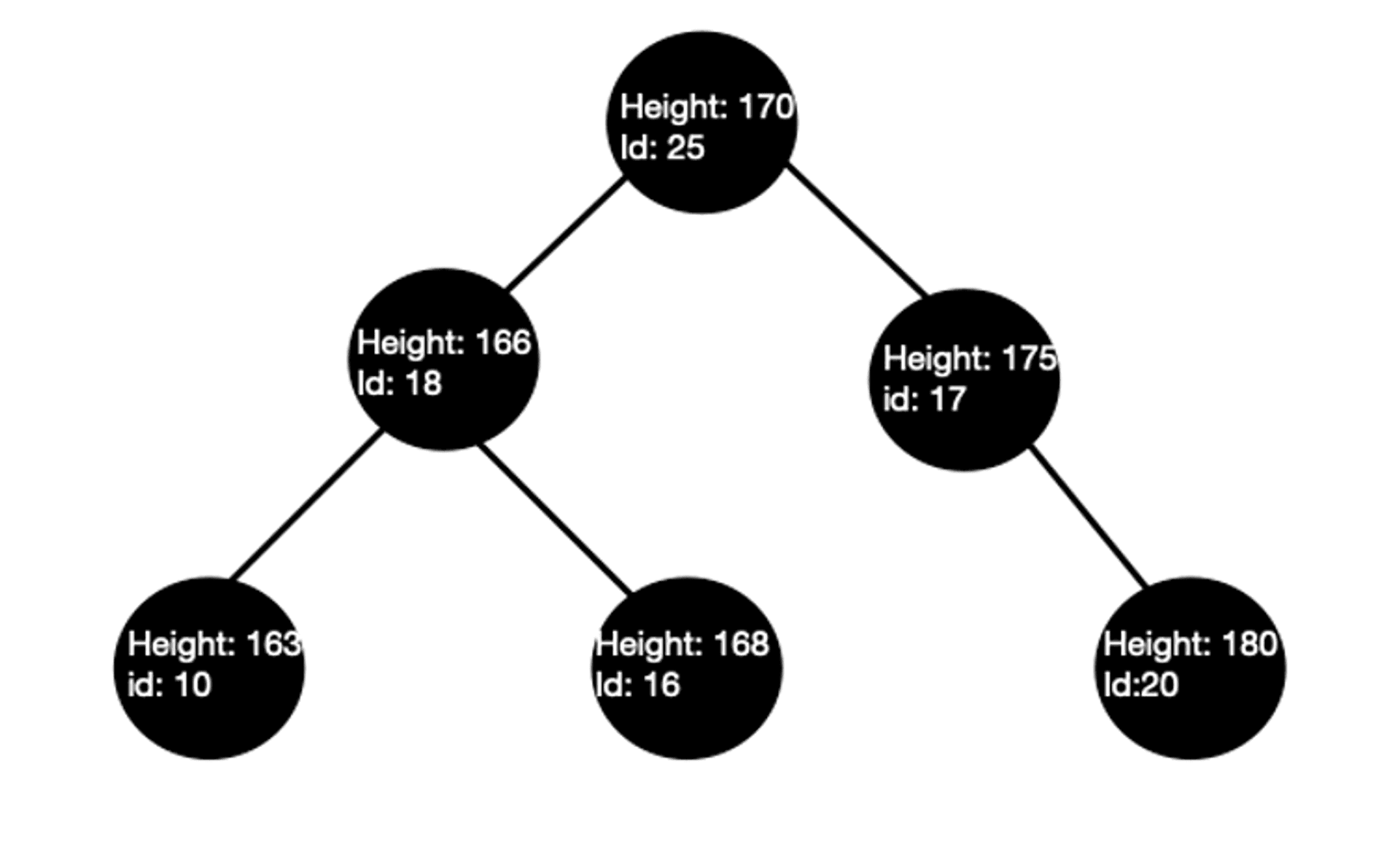
SELECT * WHERE Height > 165這個指令在查詢時就會變成先從此樹中找到符合條件的node,再用對應的clustered index(id)去圖一中的樹查詢。
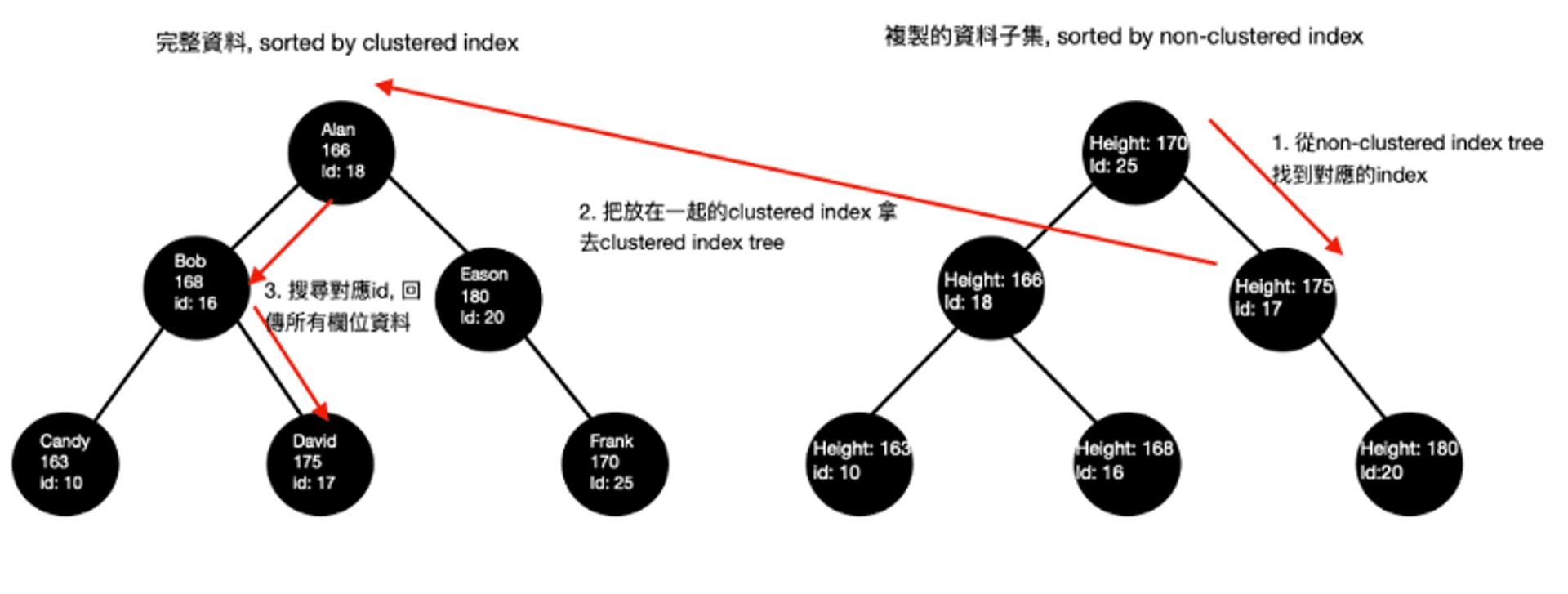
以上這個流程就是 MySQL-Innodb 中用 index 加速資料查詢的流程和原理
看來很完美! 收工~
..
…
……
然而現實總是殘酷的, 這樣的流程有個潛在的大問題。
先從 non-clustered index 取得 clustered index 再去查詢,看起來只是從查詢一次變成兩次而已, 然而實際上如果進行非常大範圍的Range Query, non-clustered index一個range中對應的clustered-index資料在實際硬碟的存放位置是非常散亂的,這個查詢clustered-index tree的步驟會在Storage中發生非常巨量的Random Access,效能的大幅下降是可以預期。
如果我們想要 Select 全部的欄位,但是卻不想要回去 clustered-index tree 裡面查詢, 有辦法嗎?
# PostgreSQL的解法:
PostgreSQL看到了 MySQL-Innodb 中這樣的痛點, 所以在設計上採取了一個策略 : 不使用 clustered index tree。
沒有 clustered index 意味著的就是完整的原始資料無法進行排序(因為沒有排序的依據) 在 PostgreSQL 的中存放完整資料的地方稱之為 Heap。 這個Heap 是個無序的結構,每一筆資料存在 storage 中是不給予這些資料順序任何的保證的。
而 non-clustered index 的部分,,PostgreSQL 則是從在每個 node 裡面儲存Clustered-index,改成儲存一個指向 Heap 中對應完整資料的 row 所在位置的指標. (注意此處的指標不是 memory 的指標,而是用來在資料庫中標記唯一所在位置的 Page 的資訊) *
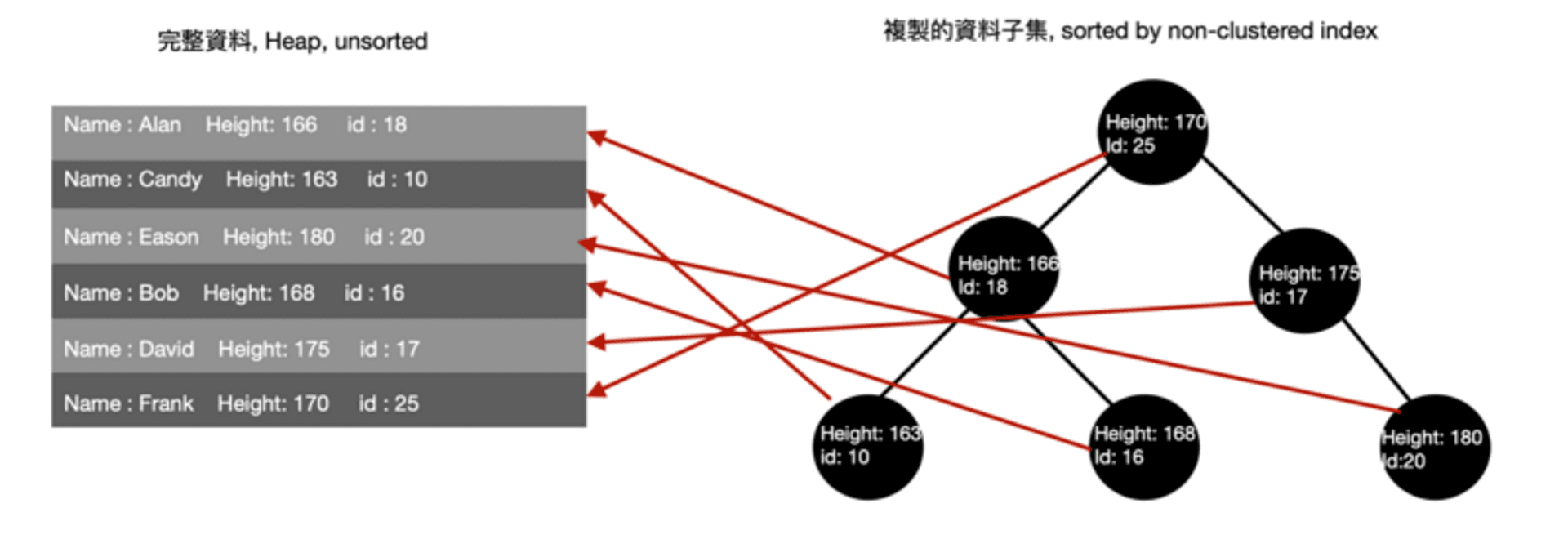
看到這裡可能會有人想問,“那為何 MySQL不也直接在 Non-clustered index tree的 node 中存放指標就好了?
這點也正是 PostgreSQL 以 Heap 存放原始完整資料的主要原因. 因為 Heap 不保證資料順序,所以任何資料被 update 或 insert ,現有的其他資料都不需要變更存放的位置, 相較之下 Innodb 因為是依照 clustered index 來排序,任何資料的 clustered index 被更改或插入新的資料都會造成其他資料的存放位置依照index 發生相對應的變化。
(以 B-Tree 來說, 會為了維持 tree 的 balance 而發生樹的結構的變化,因為clustered index 必須反映實際物理位置,所以 clustered index 順序更新必須同時更新 disk 中的資料位置, 造成大量的時間消耗)
正是因為資料位置的不變的特性,讓 PostgreSQL 的指標實現成為可能。所以在PostgreSQL 中,用 Non-clustered index 查詢資料,不需要再跑去 clustered index tree 裡面查詢,直接拿指標位置去 storage 裡面對應的 Page 取出資料即可。
然而這樣的設計並非沒有 Trade-Off 的。
儘管在用 Non-clustered Index 進行 SELECT * 之類的查詢時會因為少一次tree lookup 而有效率上的提升。但因為這種實現方式完全捨棄了 clustered-index,所以如果是用 primary key(以Innodb 來說就是 clustered index ) 來查詢, 反而會多了一個用指標查詢的步驟。
且因為 Heap 沒有辦法保證任何資料在物理上的 Locality(在前面提過, clustered index 才有辦法保證 index 跟 storage 中物理位置的相似性),所以無法像 MySQL-Innodb 一樣以 clustered-index 進行 Range Query 時有Locality的優勢。
綜上所述,我們大致可以把這兩種資料庫實現Indexing的方式用以下幾點歸納:

以剛剛包含了 id、 Name 跟 Height 的 table (person) 為例 :(當然以下的前提都是資料的 rows 非常非常多的狀況,且我們把 id、Name、 Height 都 create Index)
SELECT p.*
FROM person p
WHERE p.Height < 170;
對這樣的指令來說, 因為要 Select 全部的欄位, 而查詢條件是 non-clustered index, 所以根據我們前面所說,因為 MySQL-Innodb 還必須去 clustered index tree 裡面搜尋一遍,是可以預期 PostgreSQL 是比較快的。
SELECT p.*
FROM person p
WHERE p.id > 18;
這個指令,儘管要 Select 全部的欄位,但因為 id 是 clustered index, 用id來當作查詢條件時對 Innodb 來說就直接在 clusterd index tree 裡面搜尋了,找到就可直接回傳。而對 PostgreSQL 來說因為id仍然是 non-clusterd index (跟 Heap 分開的), 所以 PostgreSQL 反而還會多了一次用指標去資料庫把資料撈出來的步驟。 因此這樣的操作是可以預期 MySQL 是有優勢的。
SELECT p.Name
FROM person p
WHERE p.Name = "David";
至於這個指令,因為要回傳的 column 就是 non-clustered index,所以不論是Innodb 還是 PostgreSQL 都只要在查詢 non-clustered index tree 時直接回傳Name 就好了, 跟 Clustered Index tree 和 Heap 都沒關係,所以兩者的資料儲存方式不同不會讓這樣的查詢有太大效能差異。
# 結論 :
一般來說如果用 Primary Key 來查詢時,因為 MySQL-Innodb 是用 Clustered-index, 所以速度較快,尤其在進行 Range Query 時因為 clustered-index在Storage 中的 locality,所以速度會大幅提升。
而如果是需要經常對不同欄位進行檢索的 Table, 因為 PostgreSQL 在 non-clustered index 的資料結構的節點中有直接存放實際資料的位置,所以速度會比起要再次去 clustered index 資料結構查詢的 MySQL-Innodb來的快。
另外,當要 select 的欄位全部都被 include 在 non-clustered index 的資料結構中時,理論上兩者的效率便不會有太大的差別。(不過, INCLUDE clause只支援 PostgreSQL11 以後的版本,因此如果 PostgreSQL 沒有 INCLUDE 的話Innodb 還是會快一些的)
Tag
Recommendation
Discussion(login required)