想了解開發 OpenAI 會遇到哪一些坑嗎?
想了解如何解鎖 Embeddings 和 Retrieval-Augmented Generation 讓 GPT 的模型就算沒有企業獨有的 knowhow,
也能產生出有意義的內容嗎?那就快點手刀點進來吧,讓您滿載而歸!
# 前言
由 OpenAI 開發的 ChatBot 在2022年11月推出,後續對各行各業造成的影響和轟動。筆者從一個觀望的態度,開始嘗試使用一陣子,最後決定加入 ChatGPT Plus 。作為一個每日離不開 GPT 的使用者,親身體驗到其帶來的好處,不僅可以大量的加速在個人技術知識上的學習速度,工作效率,亦可以幫助在生活其他面向帶來助益,算是這幾年,經過了 3D printer, VR/AR, Web3 筆者認為最直接有幫助且進入摩擦力相對小的新技術。
目前 Cymetrics 資安產品的方向,也想利用 AI 的趨勢,為客戶提供更好的服務和價值,所以筆者有這機會來實作 AI 的產品。目前AI的服務已經發佈第一版 MVP 出去,所以有時間來寫文章,做個總結。筆者因為並非 AI 背景出生,用字遣詞如果有不精準之處,也請各位大大不吝請教和討論。
# 學到什麼?
在這文章中,主要會針對下列的主題做一些通俗的介紹
- OpenAI embeddings 基本介紹
- RAG 簡介
- AI 導入實務中所遇到的困難點
希望大家在讀完這篇文章後,能對某些想利用 RAG 和 embeddings 的開發者,能有更多的了解。
# Why
動機是我們做一件事情最核心的部分,工程是滿足此動機的手段。所以在談論比較技術的面向前,先釐清動機算是蠻必要的事情。
以一些企業端來說,通常想要的應用不會單純只是來回的問答,更多的部分反而涉及一些複雜的需求,這些需求普遍有下列可能的問題
- 目前 GPT 的 Model 缺乏公司獨有的產業知識
- 目前 OpenAI 的 GPT 的知識只到 2021 年 9 月
以上的問題可能會導致使用者從 GPT 得到看似講得有道理,但其實是沒那麼正確的內容,在生成式 AI 中這稱為『 hallucination 』。所以為了解決上述的問題,我們使用了 RAG 和 embeddings 的手段來達到我們需要的業務需求。
# What
那到底什麼是 embeddings 和 RAG 呢?
# Embeddings
Embeddings 是一種將文本向量化的手段,如下圖所示。
生活中,有時候會需要去釐清物體間的相似程度,譬如:蘋果跟香蕉相似嗎?一般來說這種問題可以在不到一秒就得到,但問題變成,請比較這兩段文字內容相似度?在兩段文字都沒看過的情況下,很可能會得到一個答案,『等我稍微看一下,才能分辨』,五分鐘後,才有機會得到一個答案。
但如果條件變成『 不管文字數目的多寡,都需要在一秒內告知這文本的相似程度呢 』?

向量可以輕鬆做到相似度的比較。一個向量是否相似,看的是向量的方向和大小。所以可以根據向量的方向輕易的去判別向量的相似程度,如下圖,大部分的人可以在一秒內知道此向量A和向量B並不同。
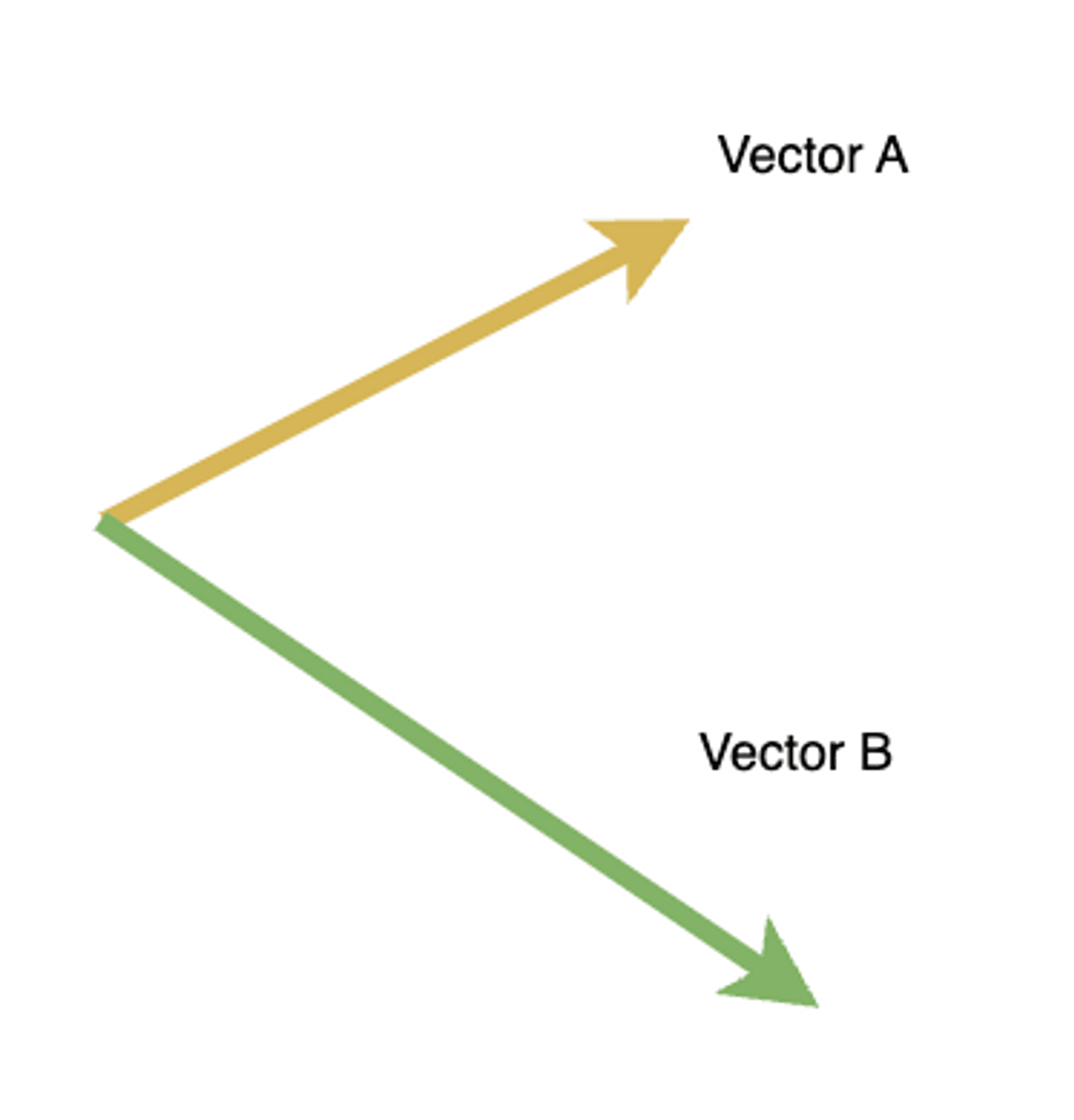
有了這個概念後,就不難理解為什麼需要 embeddings,如上面提到的,embeddings 本質上是一個將文本向量化的手段,所以當文本被向量後,我們可以透過向量比較非常快速去比較這文本相似程度。
但是,我們還需要思考向量的維度,如果向量只有一維,那好分辨嗎?例如下面這一維向量,看似一樣,但其實不然,雖然方向一樣,向量大小卻差了一些。

因此,向量維度也是判斷相似程度的一個因素,如果向量維度太低,會造成其實這向量本質上沒那麼相似,但因為維度太低(如上圖的一維陣列),導致變得很像,誤差變高。目前來說,以 OpenAI 提供的 embeddings 出來的向量維度會是1536,而 Bert-base 是768,Bert-large 則是1024。隨著向量維度的提升,我們不難知道,向量間彼此接近或碰到的機率會越來越低,除非他們有一定程度相似程度。
總結來說:
- embeddings 主要是向量化文本的一種手段
- 向量化的比較時間成本很低
- embeddings 的向量維度多寡,在一些 case 下,會影響文本相似的誤差率
# Retrieval Augmented Generation (RAG)
RAG 的概念最早出自一篇論文(https://arxiv.org/abs/2005.11401),我們這邊不會特別去解釋作者的核心想法,有興趣的朋友可以自行去研讀論文,我們這邊關注的點反而是在如何去應用 RAG 的概念在生成式 AI 上,並具體解決了什麼樣的問題。
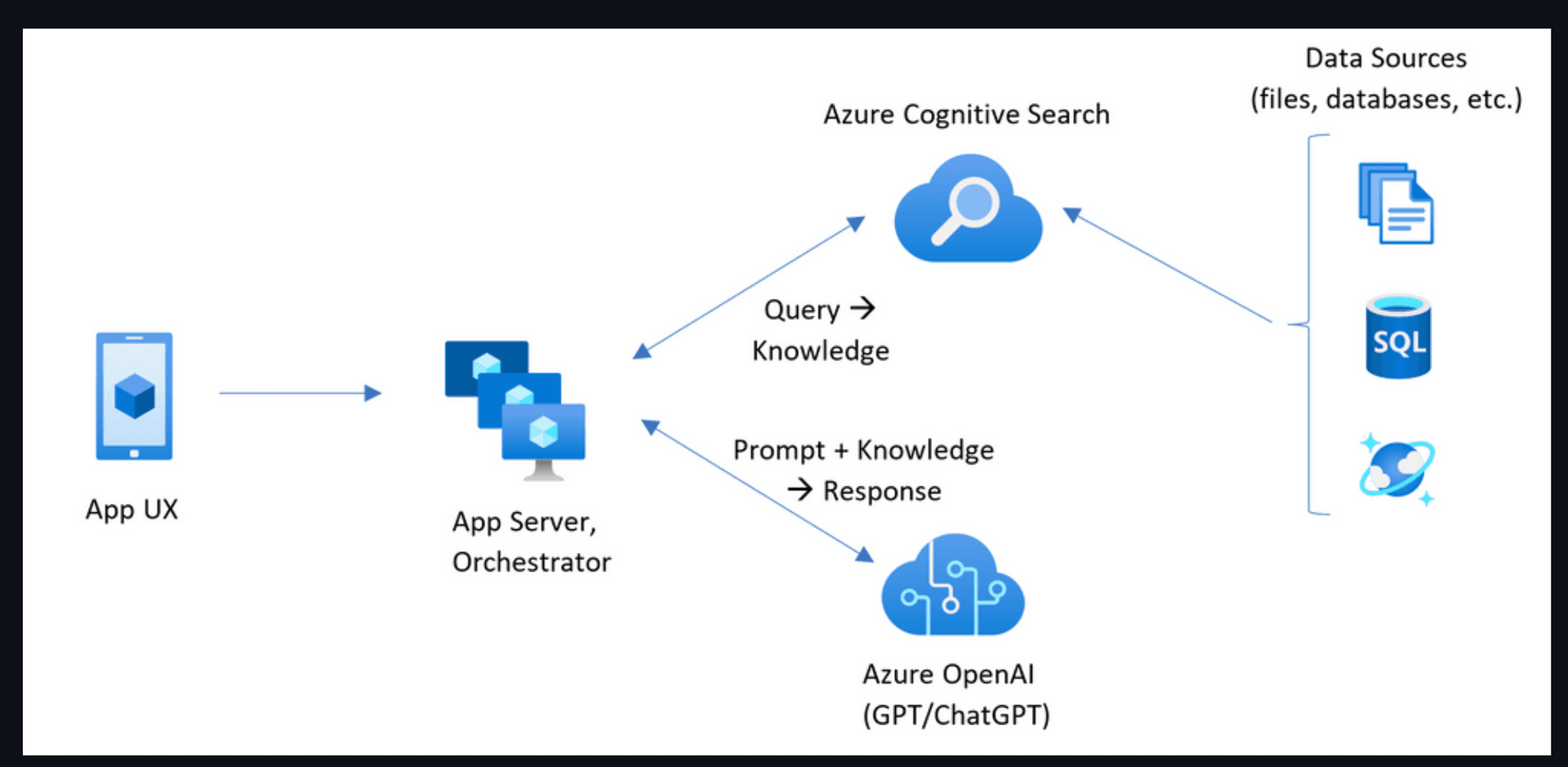
(https://github.com/Azure-Samples/azure-search-openai-demo)
上面這張圖出自 azure-search-openai-demo 這個 repository,這個 repository 就是使用RAG精神搭配 OpenAI 的生成式 AI 解決我們在上面提到的問題,在解釋這個圖之前,我們再次釐清業務目標:『GPT 可以根據我們公司自有的產業知識,和目前在2021年9月後的資料來做回答。 』,要達到這件事情,如果我們不使用 model training 的方式,我們勢必只能在客戶的 prompt 之前加上可能的答案,然後把這內容送進 OpenAI,期待 GPT 能給我們一個精確度夠高的答案。
把剛剛這段過程對應到上面的圖的話,首先,使用者會透過一個終端設備問問題,接著我們會先走上面的路徑。我們會根據使用者的問題,試著去我們企業端的資料庫中找尋可能的答案或者去搜尋引擎找尋解法,接下來,我們才會走下面的路徑,我們會將使用者的問題和剛剛找到的可能答案一起送進 OpenAI,這樣一來,GPT 在回答使用者問題時所根據的資料,不僅是企業獨有的 knowhow 以及最新的資訊,而且可以有效的降低 GPT hallucination 的程度。
# How
由上面的討論,我們現在可以理解 RAG 和 embeddings 的初步概念,接著我們要討論如何利用上面的思想去展出執行的部分細節。細節如下:
- 將公司自己的產業知識以及相關網路最新資訊透過 OpenAI 的 embeddings API進行向量化,並將向量結果上傳到向量資料庫中(ex: Pinecone)。
- 將使用者的問題,透過 OpenAI 的 embeddings API得到一組向量。切記,這組向量本質上跟使用者問的問題其實是近似的。只是它用別的表現形式表現。
- 接著會拿著第二點得到的向量去查詢向量資料庫。
- 向量資料庫會根據當初設定的匹配規則,給出跟使用者問題向量『最接近』的前幾筆向量裡面的文本內容(此文本內容會是來自企業當初向量化的產業 knowhow )
- 而此文本內容會和使用者問題合併成一個 prompt ,送進 OpenAI GPT 裏面,並等待 GPT 的回答。
以上就是 RAG 結合 embeddings 比較細節的部分,透過這個流程就可以做到讓 GPT 可以回答企業自己的 knowhow 或者是在2021/9月後才發生的事件。
# 實務上的問題
雖然 RAG 和 embeddings 看似美好,但其實離真正商業化還是有不小的距離,如果要把回答的精準度大幅提高,亦需要大量時間投入,以下是實務上開發時遇到的問題。
# 1. embeddings的資料可能需要先整理
送進去 embeddings 的資料格式或許會影響 embeddings 完的結果。目前的實務經驗,我們使用過 csv,也使用過 json 格式的資料,但最後 embeddings 的結果似乎沒有比通過資料清洗合併後的結果好。
# 2. token數目以及成本
向量資料庫是一個額外的成本。另外,送進 OpenAI 的 token 數目可能會由歷史資訊、向量資料庫獲取回來的資訊、基礎背景資訊…等所構成,因此成本上也必須要考慮清楚是否合理。由於我們業務的特殊性,我們 prompts 的 token 數目可能是萬級起跳。
# 3. 誤差
誤差是精確度最大的敵人,它可能來自幾個面向:
- Embeddings
embeddings 有一定的誤差。誤差可能原因之一,是來自選定向量相似匹配的策略,亦可能是送進去 embeddings 的資料格式或內容。
- 語言生成的天然特性
透過 embeddings 的技巧,抓取最相關的企業 knowhow 文本,GPT 亦會一定程度給出稍微有一些偏差的結論,可能可以使用 top_p 或者 temperature 來改善,但這兩個數值太低的情況,GPT 輸出的文本會太像原本企業原本的文本,通常這不會是樂見的結果,所以如何取捨又是一個問題。
- prompt太長需要分割
不管是 embeddings 或 prompt,都有單次能處理的 token 上限。但當你的文本太大的時候,就需要做切割,透過切割完的文本上下文通常不是是完整的,所以必須要做額外的補充處理,最後透過 GPT 產生的結果還需要分別作合併,但就算是如此,還是會造成精確度下降。
# 4. 品質跟回答速度
目前實際測試在 prompt 中限制的規則越多,似乎會造成 response time 越長。再者,GPT 由於帶有一定的隨機性,所以常常我們並不會只有一層的問答,可能客戶一次的問題,會有三次跟 GPT 來回的交互。舉例來說,第一層可能是過濾使用者這個問題的類型,接著根據不同的類型去使用不同的模型來處理(包含參數, Model的挑選),最後則是為品質把關或補充,這一系列為了輸出品質所做的操作都會造成 response time 拉長。
# 5. 語言的問題
就算在 prompt 指定其語言,並且下一些語氣很強的關鍵字告知 GPT 回覆的語言,但輸出的結果有時候還是會出乎你的意料之外。可能的原因為當初模型在訓練時的資料是涵蓋各個語言,所以在將答案輸出時,本質上有可能會涵蓋中文英文,所以在輸出時,是有可能會是不同語言的情況發生。
# 結論
在這篇文章中,我們對 RAG search 和 embeddings 有一些通俗的解釋,以及分享目前我們開發 AI 遇到的挑戰,希望這些東西對大家再開發 AI 上可以少踏一些陷阱,有許多地方由於篇幅關係,只能點到為止,如果反應不錯,我們會後續再針對AI的主題提出更多有趣的文章。
Tag
Recommendation
Discussion(login required)