Cache is one of the most important parts of the backend. We always use cache to improve latency. There are several things worth thinking about more before we implement cache architecture. In this article, I want to briefly discuss some of that.
# How much data should be stored in cache
Before implementing cache architecture, we have to estimate how much memory our cache needs. The 80/20 rule is the most common way to do that - 20% of objects are used 80% of the time. According to the 80/20 rule, we can cache 20% of data and improve 80% requests latency time.
For example. if there were 10M daily active users in the system and each user's metadata provided to fronted is 500k, then the size of our cache is about500k * 10M * 0.2 = 100G
Currently, the maximum memory size of the VM of each Cloud platform is about 512G, so we could use just one VM to store our cache.
Besides that in some extreme cases, we may cache all data into memory to improve latency, we must clarify the scenario first before starting design.
# Cache cluster
How if we figure out that we can not store cache data in barely one VM after estimating? Maybe we can use cache cluster like below:
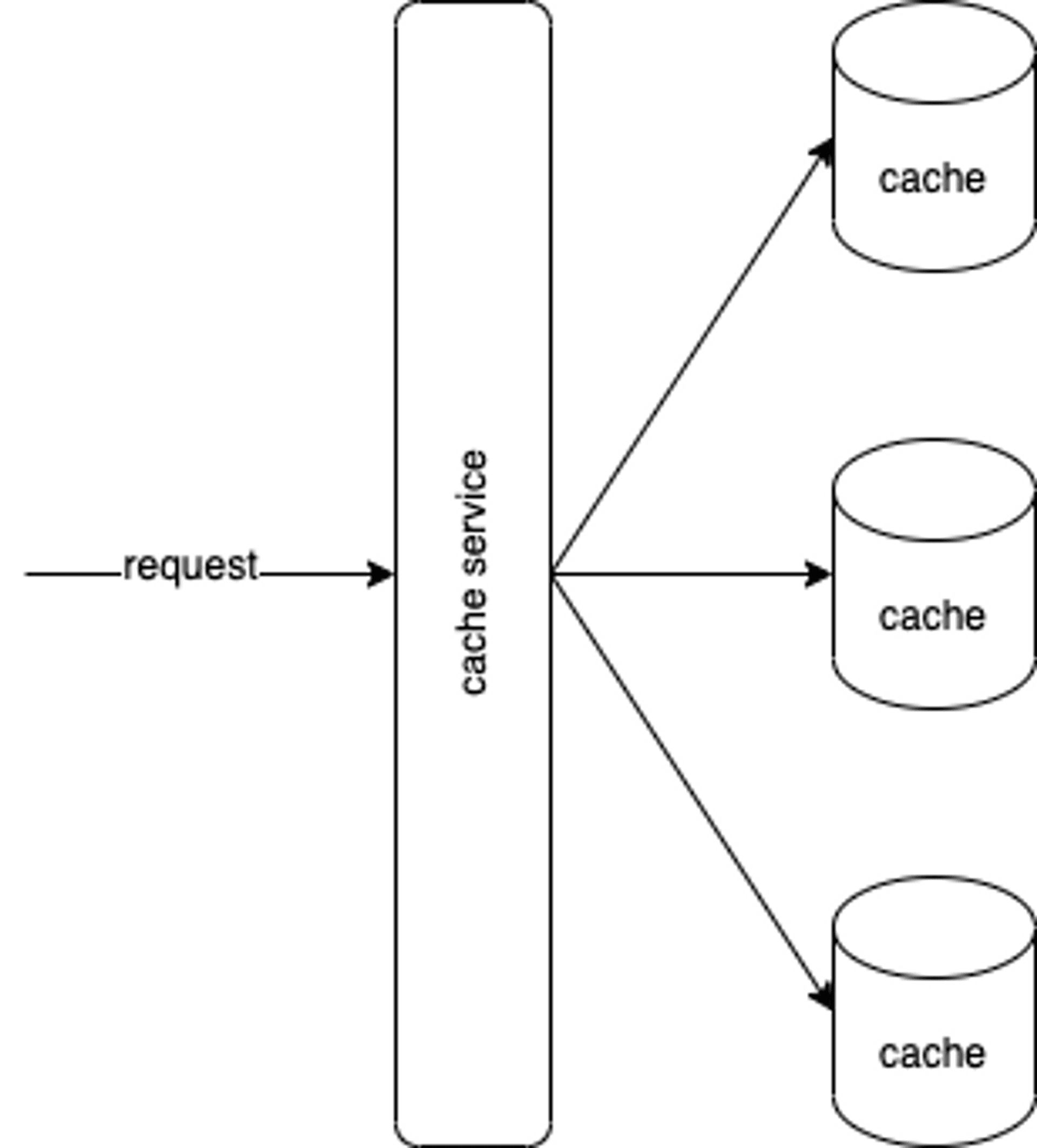
Generally, we use the hash function to find the mapping cache node. For example, we use request id as key, and use mod as hash function, we could find the mapping cache node as blow flow:
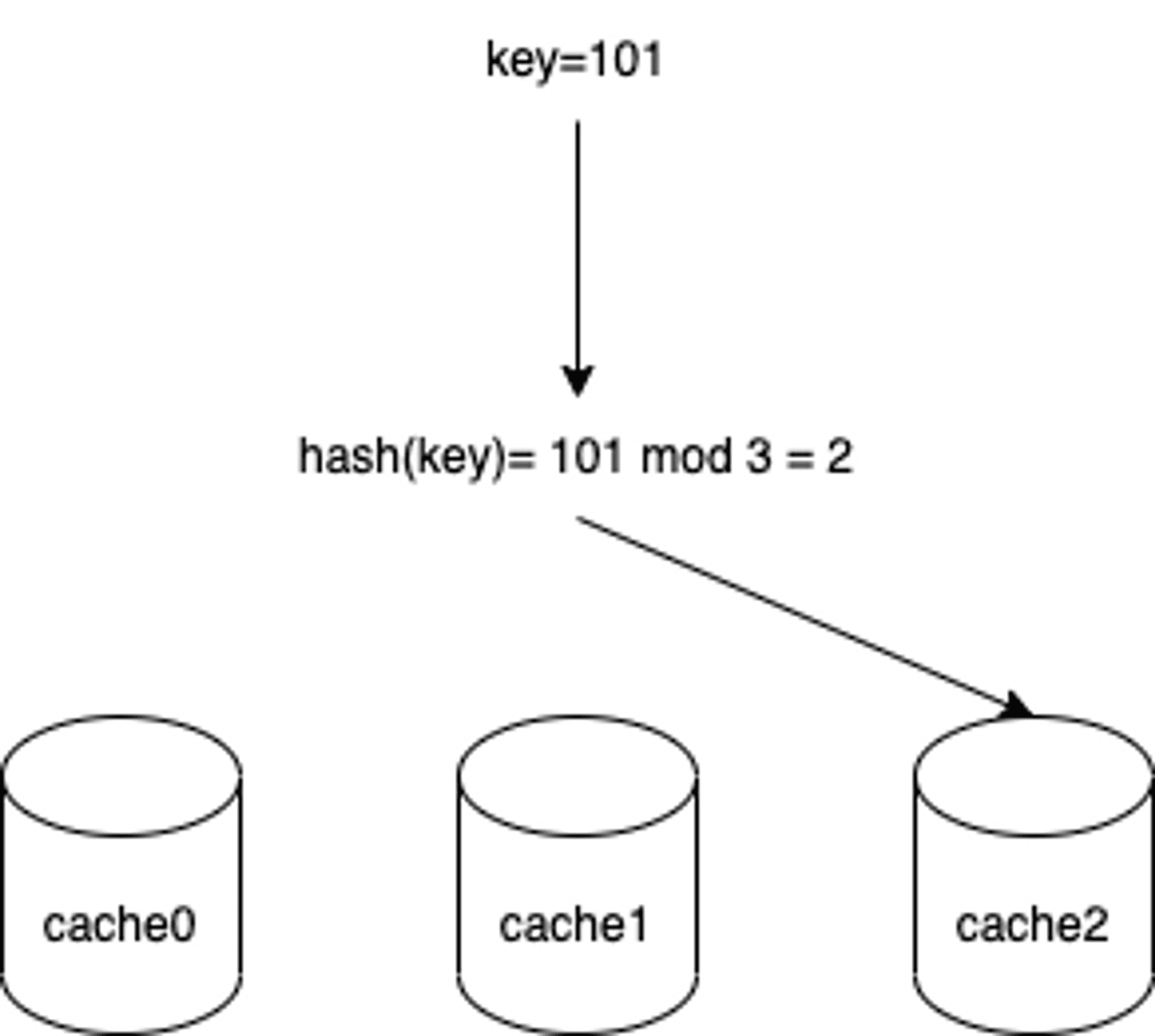
It's simple, but it also comes to some problems. If we have 3 cache nodes now, then the data distribution looks like this:
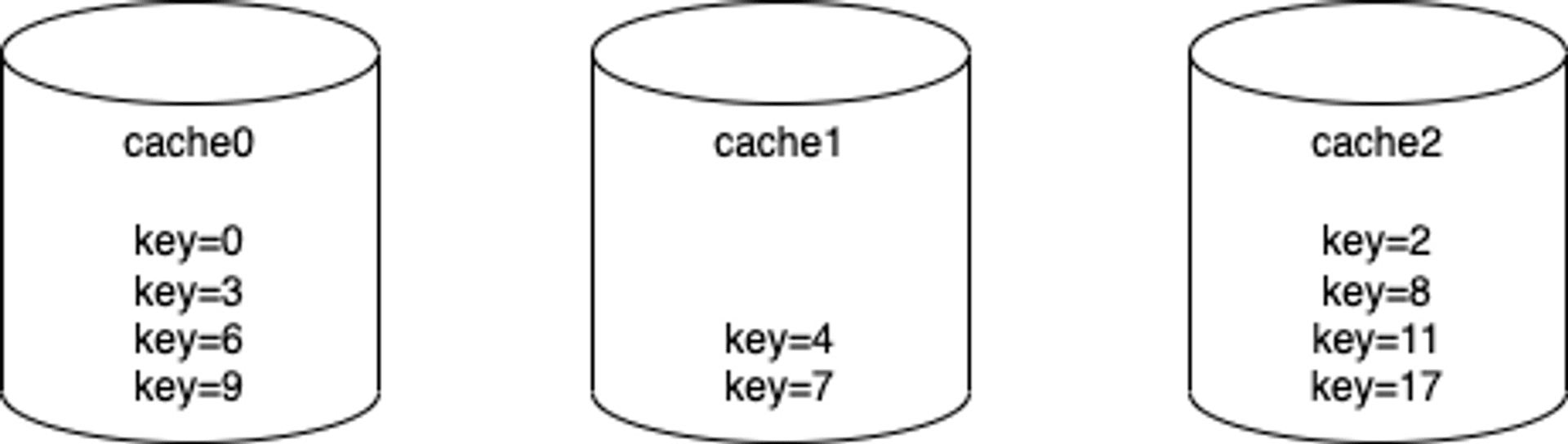
However, if we add one cache node to the cluster, then the data distribution will become like this:
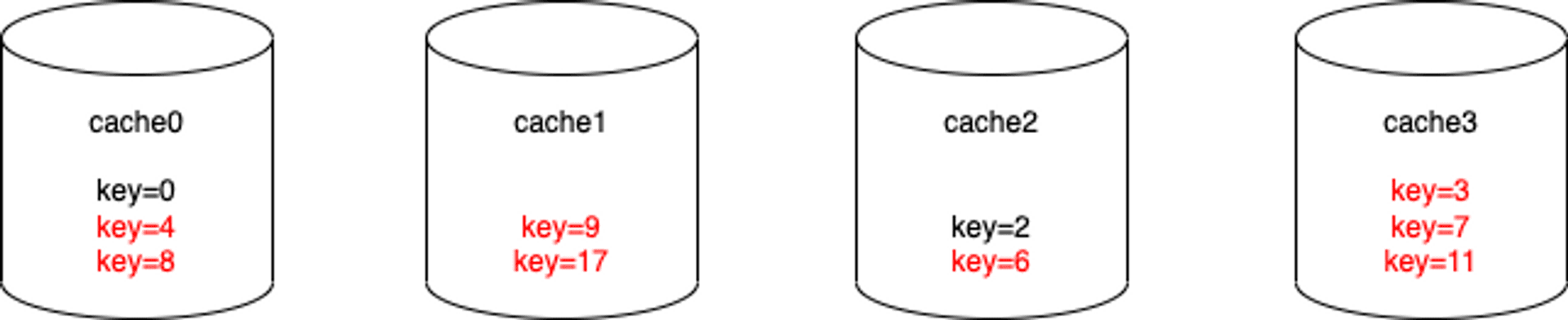
After adding one node to the cache cluster, we have to move 8 data to the mapping cache node, which makes scale up or down very suffer.
In order to minimize the number of data migration after cache cluster resizes, we can introduce consistent hashing to solve that problem.
In this article we do not descripe how Consistent hashing work, you can see more detail in wiki。
# Replacement policy
Earlier we mention that in most scenarios, we would not store all data to cache. So we need one policy to determine which data should swap out if the capacity of the cache is full. That's the cache replacement policy. There are some common policies:
- First in first out(FIFO):Those data which are stored earlier are discarded first.
- Least frequently used(LFU):Those data are used least often are discarded first.
- Least recently used (LRU):Those data that are not used recently are discarded first.
Personally, I think LRU is most commonly used.
# Update policy
Finally, let's talk about how to update the cache. There 3 policies to update cache:
- write-through: Update DB and cache at the same time. This policy provides a strong consistency between cache and DB. The disadvantage is that it would increase loading while writing data and is not recommended for the write-heavy scenario.
- write around: While writing data we only update DB and invalid cache data. When we read data we update the cache simultaneously. The disadvantage is that there may be several cache misses at the very beginning of reading.
- write back: While writing data we only update cache and write back to DB after an interval of time. This policy would improve latency and throughput in the write-heavy scenario. But the disadvantage is obvious: if the system crash before writing back, it may lose some data.
# Wrap Up
Cache exists in every level of system architecture, from hardware(CPU, Memory, and Disk), OS, Application to User fronted (Browser, app).
In This article, we discuss how to use the cache more efficiently in limited space, how to cluster for scalable, how to replace data, and how to update stale data. Through all these considerations, we can build our cache architecture more resilient, stable, efficient, and suitable for our system.
Tag
Recommendation
Discussion(login required)