Would you like to understand the pitfalls encountered in developing OpenAI?
Would you like to understand how to unlock Embeddings and Retrieval-Augmented Generation to enable GPT models to generate meaningful content, even without the unique know-how of enterprises? Then hurry up and click in, and leave with a wealth of knowledge!
# Preface
The ChatBot developed by OpenAI was launched in November 2022, and it has had a profound impact and caused a sensation across various industries. The author of this article began with a wait-and-see attitude, experimented with it for a while, and finally decided to join ChatGPT Plus. As someone who uses GPT daily, the author has personally experienced its advantages. It can substantially accelerate learning in personal technical knowledge and improve work efficiency and can also assist in other aspects of life. It is considered one of the most directly helpful and frictionless new technologies in recent years, following 3D printers, VR/AR, and Web3.
Cymetrics is also aiming to leverage the trend of AI to provide better services and values to clients with their cybersecurity products. Hence, the author had this opportunity to implement AI products. The first MVP version of our AI service has been released, so the author has time to write articles and make a summary. Since the author does not have a background in AI, any inaccuracies in wording are open for correction and discussion.
# What Will We Learn
In this article, a straightforward introduction will mainly be given to the following topics:
- Basic introduction to OpenAI embeddings
- Brief overview of RAG
- Difficulties encountered in implementing AI in practice
Hopefully, after reading this article, developers who wish to use RAG and embeddings will gain a better understanding.
# Why
Motivation is the core part of why we do something, and engineering is the means to satisfy this motivation. So, clarifying the motivation is quite necessary before discussing the more technical aspects.
From the perspective of some enterprises, the desired applications are usually not just simple Q&A. More often, they involve some complex requirements, which might generally include the following issues:
- Current GPT models lack company-specific industry knowledge
- The knowledge of OpenAI’s GPT is only up to September 2021
These problems might lead users to receive seemingly logical but not so accurate content from GPT, known as "hallucination" in generative AI. To solve the above problems, we have used RAG and embeddings to meet our business needs.
# What
So, what exactly are embeddings and RAG?
# Embeddings
Embeddings are a means of vectorizing text, as shown in the following diagram.
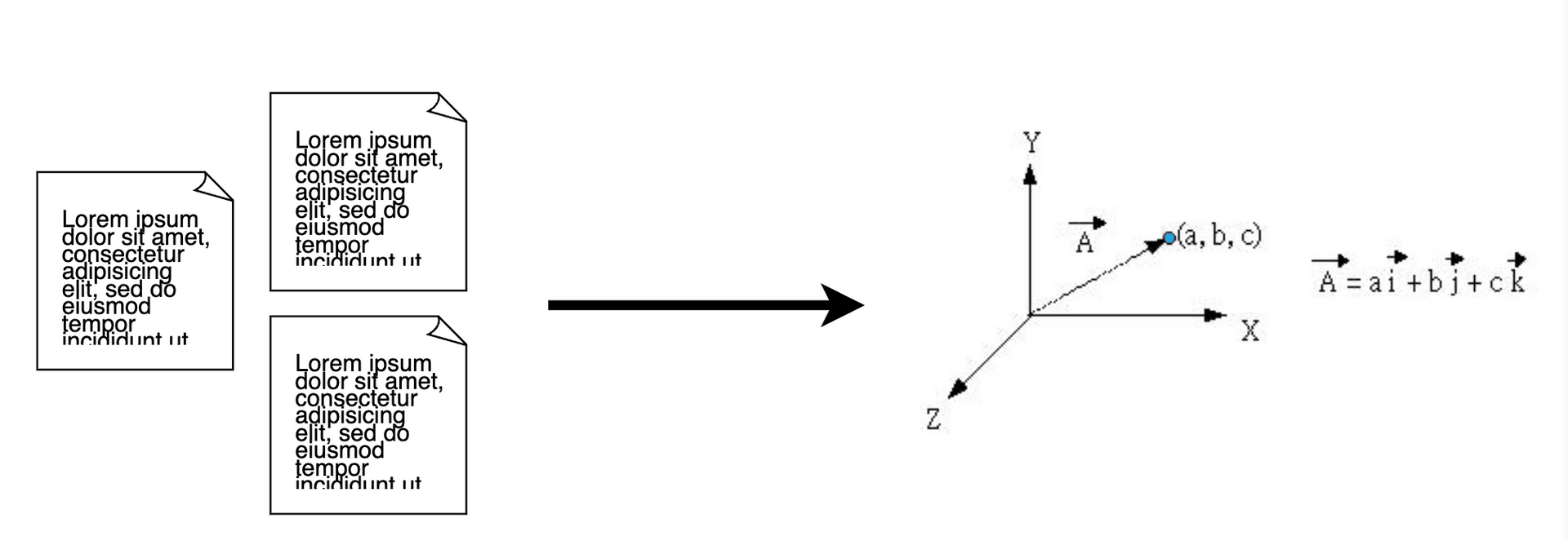
In life, sometimes, we need to clarify the similarity between objects, for example, "Are apples and bananas similar?" Generally, this kind of question can be answered in less than a second. But when the question becomes more complex, like “Could you compare the similarity of these two paragraphs?” If both paragraphs are unseen, the answer will likely be, "Let me take a quick look before I can distinguish," and an answer might be available five minutes later.
But what if the condition becomes "Regardless of the amount of text, the similarity of this text needs to be informed within one second?"

Vectors can easily accomplish comparisons of similarity. The similarity of two vectors depends on both their direction and magnitude. Therefore, one can easily discern the degree of similarity between vectors based on their direction. For instance, as shown in the following diagram, most people can tell within a second that vector A and vector B are not the same.
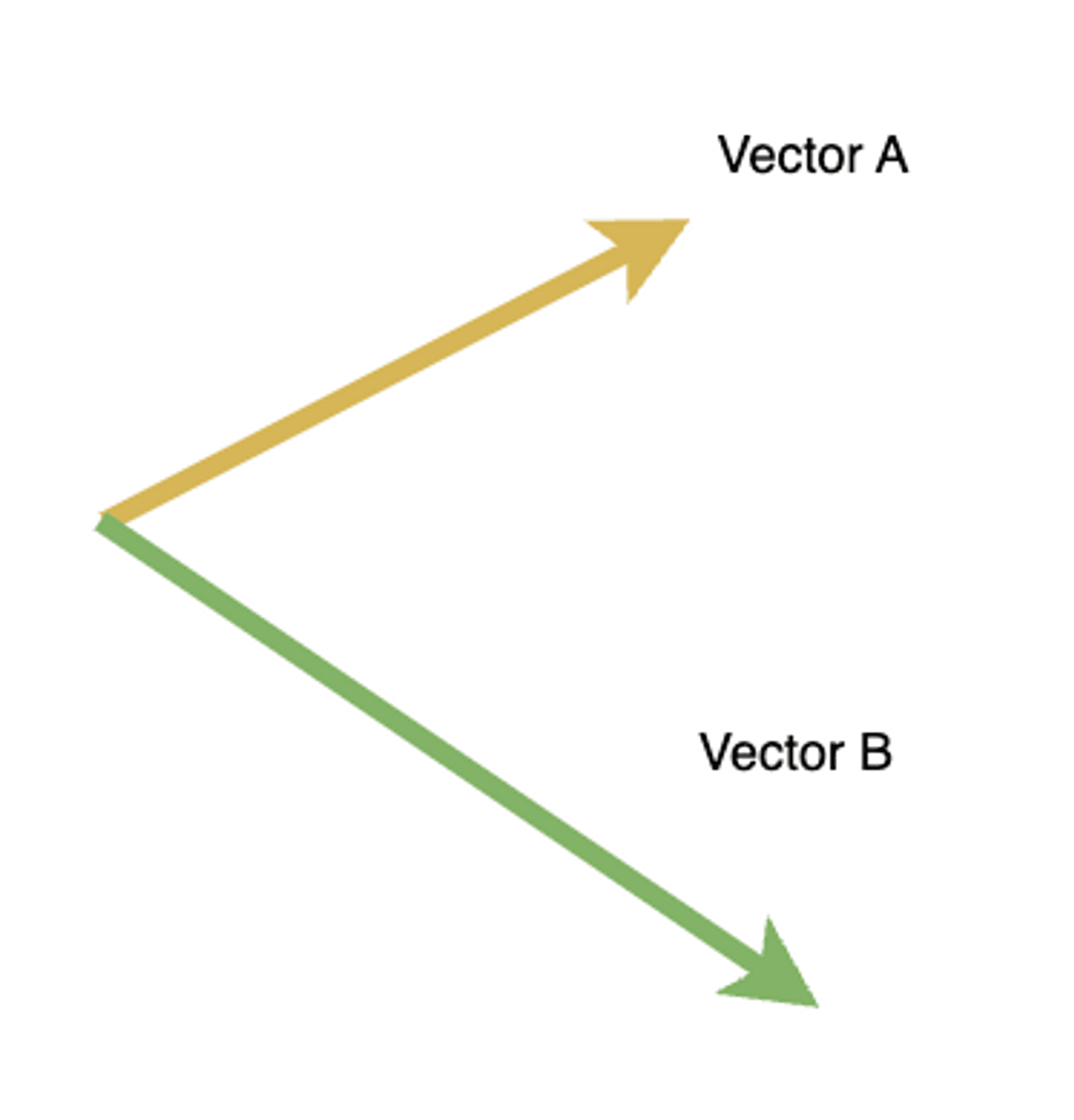
With this concept in mind, it’s not hard to understand why embeddings are needed. As mentioned above, embeddings are essentially a means to vectorize text. So, once the text is converted into vectors, we can very quickly compare the degree of similarity between texts through vector comparison.
However, we also need to consider the dimension of the vector. If a vector is only one-dimensional, is it easy to distinguish? For example, the one-dimensional vectors below seem to be the same, but they are not. Although the direction is the same, the magnitude of the vectors differs slightly.

Thus, the dimensionality of vectors is also a factor in determining the degree of similarity. If the vector dimension is too low, it may lead to high resemblance between vectors that are not inherently very similar, due to the low dimensionality (as shown in the above one-dimensional array), increasing the margin of error. Currently, the vector dimension for embeddings provided by OpenAI is 1536, while for Bert-base it is 768, and for Bert-large, it is 1024. With the increase in vector dimensions, it is not hard to understand that the probability of vectors being close to or intersecting with each other becomes increasingly lower, unless they have a certain degree of similarity.
In conclusion:
- Embeddings are primarily a means of vectorizing text.
- The time cost of comparing vectorized entities is very low.
- The number of dimensions in embeddings, in some cases, can affect the error rate of text similarity.
# Retrieval Augmented Generation (RAG)
The concept of RAG originated from a paper (https://arxiv.org/abs/2005.11401). We will not delve into explaining the core idea of the author here. Interested readers can study the paper themselves. Our focus here is on how to apply the concept of RAG in generative AI and what specific problems it solves.
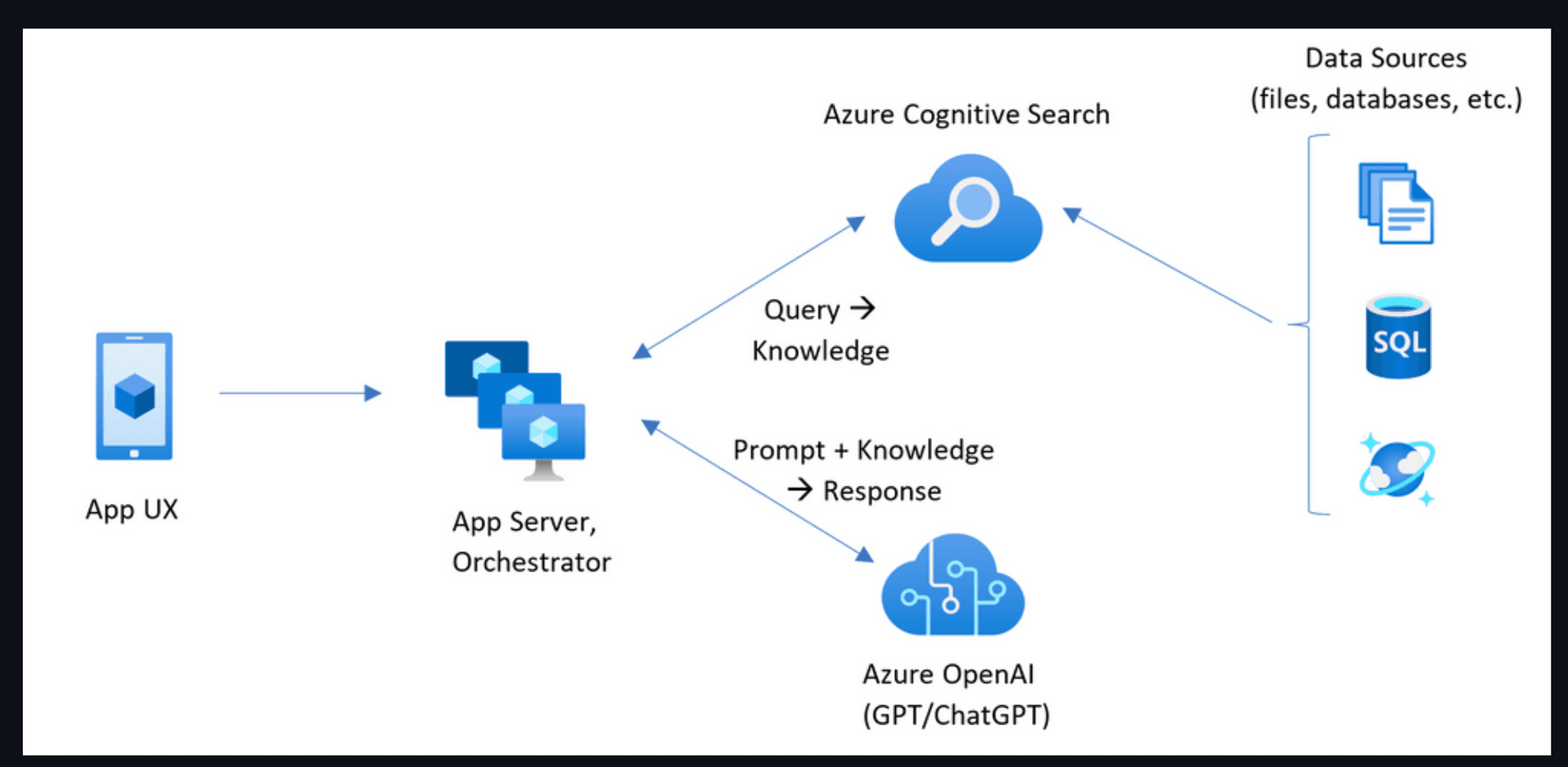
(https://github.com/Azure-Samples/azure-search-openai-demo)
The image above is from the azure-search-openai-demo repository. This repository utilizes the spirit of RAG in conjunction with OpenAI's generative AI to solve the problems mentioned above. Before explaining this image, let’s clarify our business objective again: “GPT can answer based on our company’s proprietary industry knowledge and data post-September 2021.” To achieve this, if we do not use model training, we inevitably have to add possible answers before the client’s prompt and then send this content into OpenAI, hoping GPT can give us an answer with high precision.
Mapping the above process to the image, first, users will ask questions through a terminal device. Then we will take the path above. We will try to find possible answers in our enterprise database based on user questions or search for solutions using a search engine. Next, we will take the path below. We will send the user's question and the possible answers found to OpenAI.
Thus, the data that GPT relies on to answer user questions includes not only the enterprise's unique knowledge and the latest information but also serves to effectively reduce the degree of GPT hallucination.
# How
From the above discussion, we can now understand the preliminary concepts of RAG and embeddings. Next, we will discuss how to implement the detailed parts using the ideas above. Details are as follows:
- Vectorize the company's industry knowledge and the latest relevant online information using OpenAI's embeddings API and upload the vector results to a vector database (e.g., Pinecone).
- Obtain a set of vectors for the user's question using OpenAI's embeddings API. Remember, this set of vectors is similar to the question asked by the user. It's just presented in another form.
- Then, use the vector obtained in step two to query the vector database.
- The vector database will, based on the initially set matching rules, give the texts inside the vectors "closest" to the user's question vector (this text content will be from the industry knowhow vectorized by the enterprise initially).
- This text content will be combined with the user's question into one prompt, sent into OpenAI GPT, and we will wait for GPT's answer.
The above are the more detailed parts of combining RAG with embeddings. Through this process, GPT can answer based on the enterprise’s knowhow or events occurring after September 2021.
# Practical Issues
Although RAG and embeddings seem promising, there is still a considerable distance from true commercialization. If we want to substantially improve the precision of the answers, significant time investment is also needed. Below are the issues encountered in practical development.
# 1. Data for embeddings may need prior organization
The format of the data sent into embeddings may affect the results after embeddings. From current practical experience, we have used CSV and JSON-formatted data, but the final results of embeddings seem no better than those obtained after data cleaning and merging.
# 2. Token number and cost
The vector database is an additional cost. Also, the number of tokens sent into OpenAI may consist of historical information, information retrieved from the vector database, basic background information, etc., so cost considerations must also be clear and reasonable. Due to the peculiarities of our business, our prompts' token numbers may start in the tens of thousands.
# 3. Error
Error is the greatest enemy of precision; it might come from several aspects:
- Embeddings
Embeddings have a certain error. One possible reason for the error is the strategy chosen for vector similarity matching; it might also be the format or content of the data sent into embeddings.
- Inherent nature of language generation
Through the technique of embeddings, grabbing the most relevant enterprise knowhow text, GPT will also give conclusions with a slight deviation to a certain extent. It might be improved using top_p or temperature, but if these two values are too low, the text output by GPT will be too similar to the original text of the enterprise, which usually is not a desirable result, so how to choose is another problem.
- Need to split if the prompt is too long
Both embeddings and prompt have a single handling token limit. But when your text is too large, it needs to be split. Through the split text, the context is usually not complete, so additional supplementary processing is needed, and finally, the results generated by GPT also need separate merging. But even so, it will still cause a decline in precision.
# 4. Quality and response speed
From current actual testing, the more rules are limited in the prompt, the longer the response time seems to be. Moreover, due to the inherent randomness of GPT, often we don’t have only one layer of Q&A; a customer's question might have three interactions with GPT. For instance, the first layer might be filtering the type of user's question, then different models are used to process according to different types (including parameters, model selection), and finally, it is for quality control or supplement. This series of operations done for output quality will cause a prolongation of response time.
# 5. Language issues
Even if the language is specified in the prompt, and some strong tone keywords are used to inform GPT of the reply language, the output results sometimes will still be unexpected. A possible reason is that the training data of the original model covered various languages, so when outputting the answers, it inherently might include Chinese and English. So, different languages might occur in the output.
# Conclusion
In this article, we have some common explanations about RAG search and embeddings and share the challenges we encountered in developing AI. We hope these things can help everyone avoid some pitfalls in developing AI. Due to the length of the article, many places are only mentioned briefly. If the response is good, we will subsequently provide more interesting articles on AI topics.
Tag
Recommendation
Discussion(login required)