快取是後端系統提升 latency time 最常用的手段之一。在設計快取架構時有幾個值得注意的點,這篇文章會簡單討論這些細節在實作上常見的策略。
# 快取多少資料?
在規劃快取時,我們需要先評估要快取多少資料在記憶體。尤其在有大量資料的系統,我們可以根據事前評估需要的記憶體大小,決定快取是否需要使用 cluster cache。
常見的評估方法是利用 80/20 法則 - 80% 的流量由 20% 的資料造成。基於 80/20 法則下,預期快取 20% 的資料可以提升 80% 的 request latency time。舉例來說,如果我們的系統每天有 10M 個活躍用戶,每個用戶提供給前端系統使用的 metadata 為 500k,那我們需要快取的資料為:500k * 10M * 0.2 = 100G
目前雲端供應商的 VM 規格記憶體最大約在 512G 左右,因此一台 VM 的規格即可應付。值得一提的是,在某些極度要求 request lanency 的場景下,將全部資料塞到快取也是可以接受的做法,在設計快取架構時還是需要先明確目標。
# Cache cluster
有時候評估完所需要的快取空間後發現無法塞到一台機器裡面,這時候我們會想要一個 cache cluster 來分散記憶體需求到多台機器。架構上可能會像這樣有一台服務幫忙將 request 導到對應的 cache 上要資料。
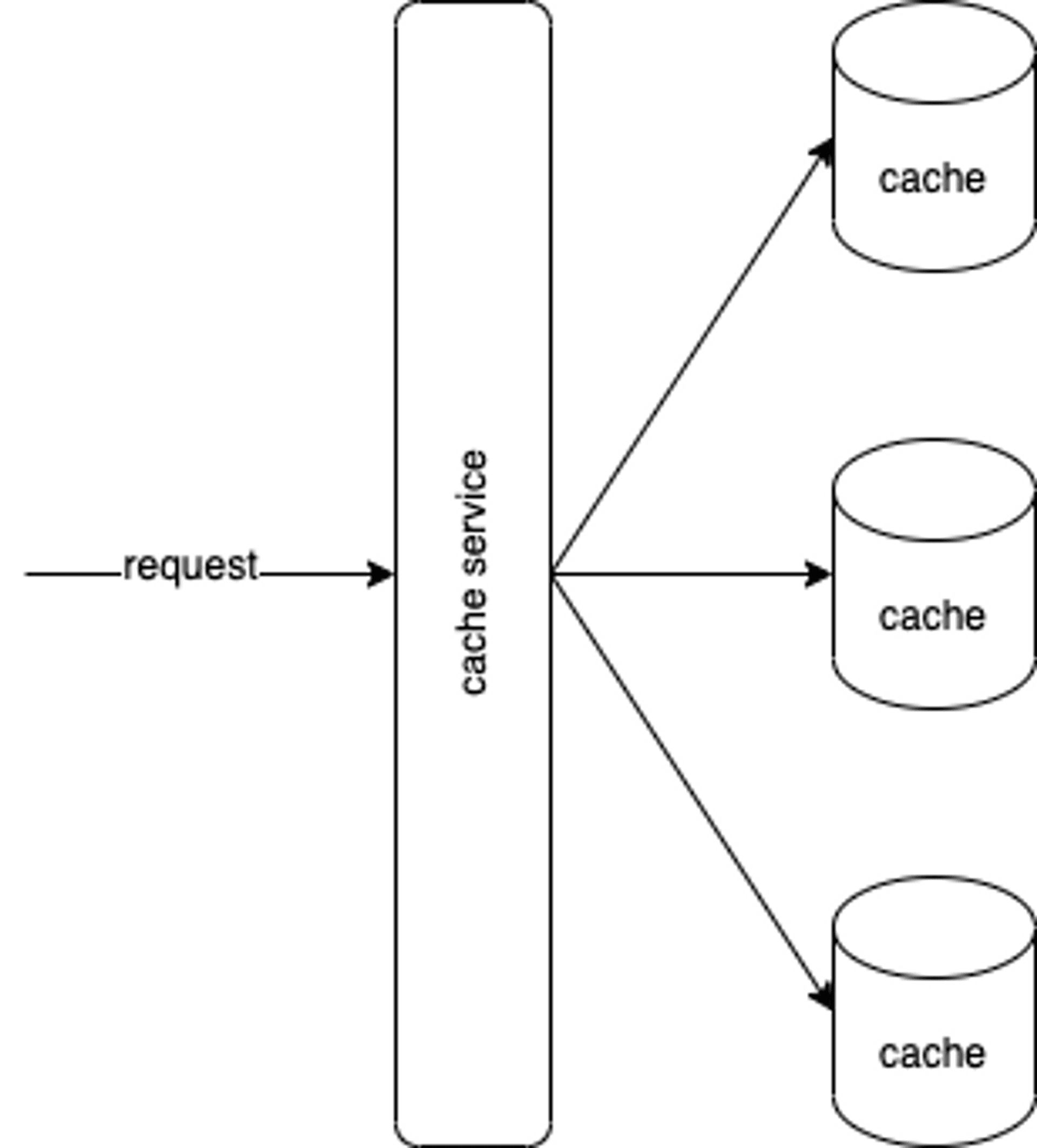
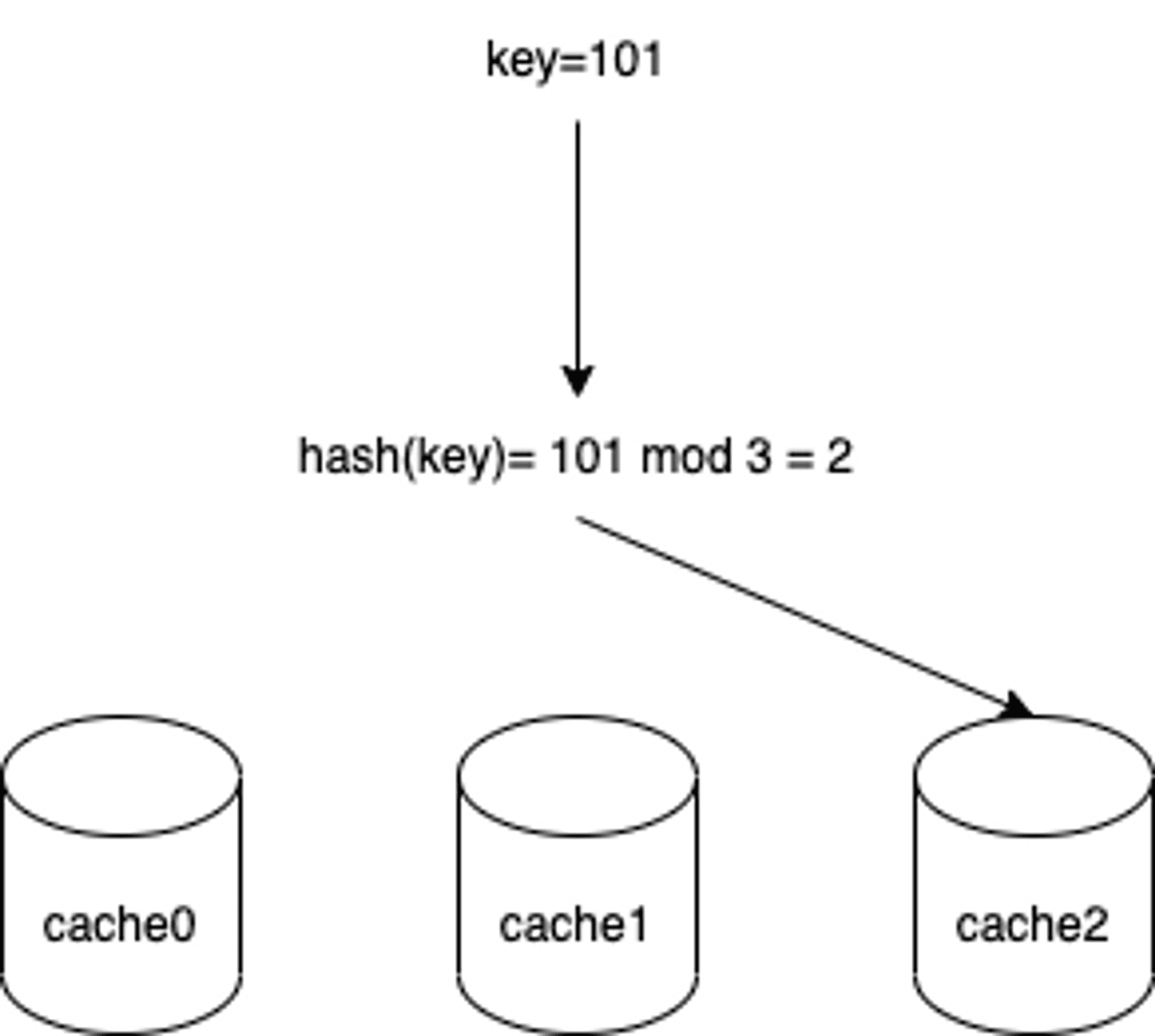
而為了讓 cache service 知道那個 request 要去那個 cache 拿資料,通常我們會使用 hash 機制,例如我們以 request-id 做 hash key,用 mod 做 hash function,如下:
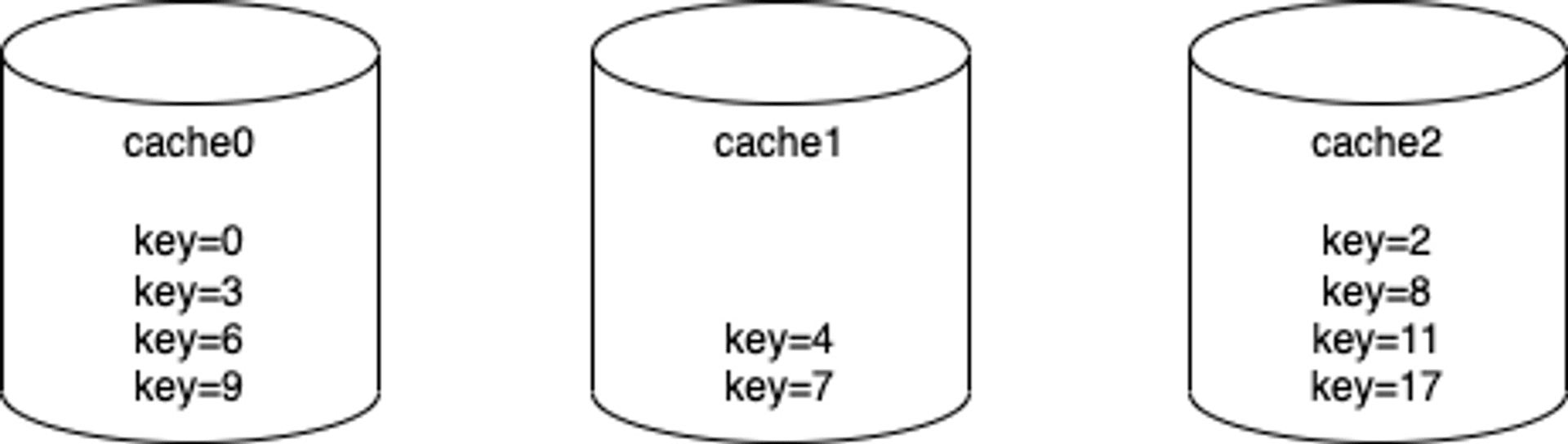
但這樣會有個問題,新增或刪減 cache cluster 內的 node 數量時會造成大量資料搬遷。舉例來說,假設目前 cache cluster 的資料如下:
如果新增一台 cache 到 cluster,資料分布就會如下:
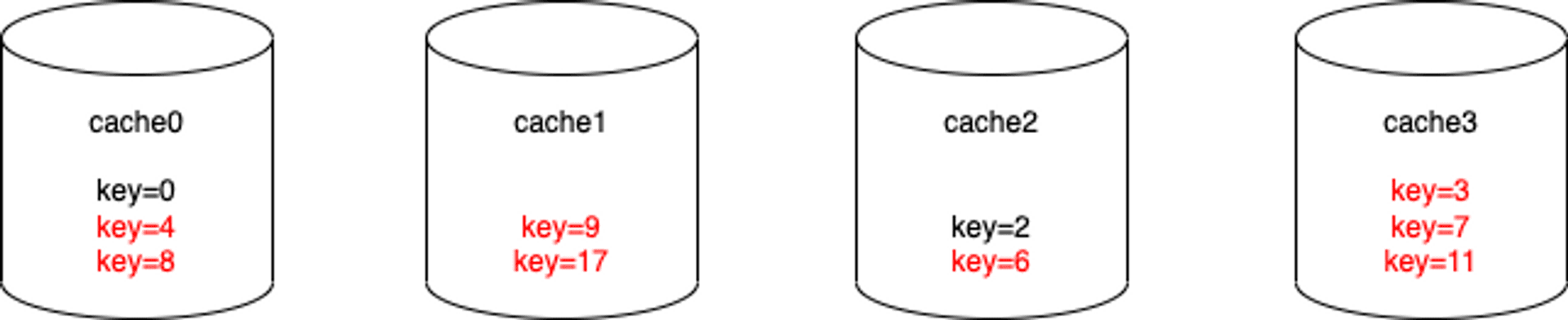
可以看到單純新增一台 cache 以後,會有八筆資料需要搬遷到正確的 cache node 上,這樣的 cache cluster 對水平擴展是極度不友善的。
上述的問題主要是因為 cache cluster node 數量變化導致 hash 後的位置不一致。為了解決這問題,可以使用 Consistent hashing 減少 node 數量變化時需要搬遷的資料數量。
Consistent hashing 運作機制不在本篇文章討論範圍,詳細演算法可以參考 wiki。
# 替換策略
前面提到通常我們不會將全部的資料都存到快取裡面,而會給快取一個容量限制。當快取內的資料到達容量上限時,需要一個策略決定要替換掉那個資料。常見的策略有:
- 先進先出演算法(FIFO):最早進入快取的資料優先替換
- 最少使用演算法(LFU):使用次數最少的快取優先替換掉
- 最近最少使用演算法(LRU):最近最少使用的內容作為替換物件
# 更新策略
當資料更新時,快取內的資料也需要更新,避免用戶讀取到就資料。常見的更新策略有:
- write-through:在更新 DB 資料的時候同步更新快取資料,這策略將會大幅保證資料一制性,缺點是會增加更新資料的 loading,在頻繁更新資料的場景中不建議使用。
- write around:在更新資料時僅更新 DB,直到用戶需要讀取資料時才同時更新快取;缺點是在更新完資料的前幾次讀取可能會有 cache miss,造成 request 直接存取 DB。
- write back:更新資料時僅更新快取資料,而在一段時間後將所有更新資料一起寫回 DB,這策略在 write heavy 的場景看大福提升 latency 和 throughput;缺點是若在快取寫回 DB 前快取系統異常,會有資料遺失的風險。
# 總結
快取存在在系統架構的每一層中,硬體 (CPU,硬碟)到作業系統,從 backend Application 到用戶端 (browser,app)。這本篇文章中,我們討論了怎麼有效的利用快取有限的空間,如何讓快取架構可水平擴展、快取資料的替換策略以及快取資料的更新策略。透過思考這些策略,可以更好的幫助我們實作更符合自己使用情境的快取架構。
Tag
Recommendation
Discussion(login required)